共享内存多线程
本讲阅读材料
教科书 (Operating Systems: Three Easy Pieces, OSTEP) 第 25-27 章。
请大家动手尝试基于 threads.h 的编程。课堂上已经给出了一些例子:
例如,你可以试试在不同的编译选项 (O0, O1, O2) 下运行的结果有什么不同;用 objdump 查看
__thread的 “线程本地变量” 是如何在 x86-64 系统上实现的;自己试着去写一个 “山寨支付宝”,在不同的地方插入一些延迟for (volatile int i = 0; i < DELAY; i++)改变线程的调度,然后观察到底会发生什么结果。纸上得来终觉浅,绝知此事要躬行。
关于并发多线程的概念性内容,在此不再赘述,请大家阅读教科书。
1. 迷你线程库
我们对 POSIX 线程做了一定的封装,这样可以更方便地写一些 (单文件的) 小程序,实际体验一下多线程编程。代码参考 threads.h,它只有两个 API:
void create(void *fn); // 创建一个线程立即执行,入口代码为 void fn(int tid);
void join(void (*fn)()); // 等待所有线程执行结束后,调用 fn
1.1. threads.h 的实现
线程的主要数据结构是
struct thread {
int id; // 从 1 开始的线程号
pthread_t thread; // pthreads 线程号
void (*entry)(int); // 线程的入口函数
struct thread *next; // 链表
};
线程创建非常简单,分配一个 struct thread 对象,并插入链表头部,然后使用 pthread_create 创建一个 POSIX 线程 (请 RTFM)。如果系统中有多个处理器,线程允许被调度在不同的处理器上并行执行。
void create(void *fn) {
struct thread *cur = (struct thread *)malloc(sizeof(struct thread));
assert(cur);
cur->id = threads ? threads->id + 1 : 1;
cur->next = threads;
cur->entry = (void (*)(int))fn;
threads = cur;
pthread_create(&cur->thread, NULL, entry_all, cur);
}
注意到 pthread_create 创建线程需要传入函数的入口地址,函数原型:
void *func(void *arg);
即允许给线程传递一个 void * 参数,并允许线程返回一个指针。但我们的线程库支持的线程函数原型稍有不同:
void func(void tid);
为了用 ptheads 实现我们的 create,我们定义了 wrapper function,作为所有 POSIX 线程统一的入口,它会得到相应的 thread object,然后调用其中的 entry function。
static inline void *entry_all(void *arg) {
struct thread *thread = (struct thread *)arg;
thread->entry(thread->id);
return NULL;
}
在 main 函数返回后,调用 join_all,其中对所有线程调用 pthread_join 等待完成,最后调用注册的回调函数 (callback)。下面的代码里使用了非标准的 __attribute__,libc 为我们提供了 portable 的实现 atexit。
void join(void (*fn)()) {
join_fn = fn;
}
__attribute__((destructor)) void join_all() {
for (struct thread *next; threads; threads = next) {
pthread_join(threads->thread, NULL);
next = threads->next;
free(threads);
}
join_fn ? join_fn() : (void)0;
}
思考题:
atexit(3)我们已经在第一次代码课和本次课介绍了注册在 main 函数结束之后执行的 callback。请大家查看
atexit函数的手册,编写一个小程序使用atexit。一个额外的问题:
如果
main函数执行期间发生了非法操作,例如执行非法的 pointer dereference:*(int *)NULL = 0;
atexit注册的 callback 是否还会被运行?这符合你的预期吗?
迷你线程库封装了 fork-join model 的线程,就像 “fork (叉子)” 一样创建出多个执行路径,最后等待它们执行完毕后汇聚在一起。
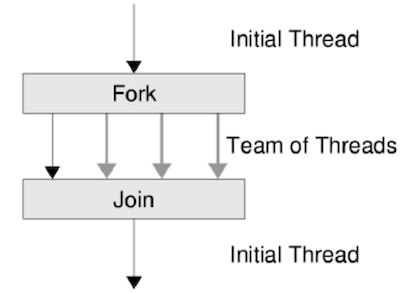
1.2. 多线程编程
有了迷你线程库,我们很容易创建多个共享内存的线程 (线程拥有独立的寄存器和堆栈)。
#include <threads.h>
void f() {
static int x = 0;
printf("Hello from thread #%d\n", x++);
while (1); // make sure we're not just sequentially calling f()
}
int main() {
for (int i = 0; i < 1000; i++) {
create(f);
}
join(NULL);
}
上述程序帮助我们确认:
x的确是共享的,不同的线程打印出了不同的数字;- 线程的确是并发/并行的,否则按顺序调用
f()将会进入死循环。
此外,创建线程的代价相对较低,在系统里创建数千个线程也不是问题,一旦有 CPU 空闲,线程就能开始执行,因此线程可以用来并发地处理大量在 I/O 设备上有延迟的请求。网络上的 Denial of Service 攻击通常都是由分布在各地的很多机器 (bot-net)、每个机器启动大量线程发起的。如没有特定的防御,服务器将会立即被大量的数据冲垮。
在大家对 threads.h 感到熟悉以后,不妨可以再试一试直接用 pthreads 编程,它提供了更灵活的控制,例如可以为线程指定堆栈 (这样就不用受系统默认栈大小的限制了)。
2. 并发编程的难题
多个线程共享内存,因此对共享变量的访问就会形成 “竞争” (races),例如以下这个例子是两个线程求 $1+1+\ldots+1$ ($2n$ 个 $1$):
#define n 100000000
long sum = 0;
void do_sum() {
for (int i = 0; i < n; i++) sum++;
}
void print() {
printf("sum = %ld\n", sum);
}
int main() {
create(do_sum);
create(do_sum);
join(print);
}
执行结果:
gcc -O0(8.726s) sum = 1054212206gcc -O1(0.388s) sum = 1000000000gcc -O2(0.002s) sum = 2000000000

呃……我们来看看为什么。
2.1. 操作系统:原子性的丧失
gcc -O0 的结果告诉我们:看似 sum++ 是一条语句,但实际执行的时候,它并不是一条 “原子” 不可分割的语句,而是更像如下三条语句,且随时肯能被打断:
tmp = sum;
tmp += 1;
sum = tmp;
操作系统中可以同时载入多个进程 (线程),多个线程可以在不同的处理器上并行执行。即便没有多个处理器,线程运行了一段时间之后,也可能在中途被中断,操作系统可能会调度另一个线程执行:
// sum = 10
(thread1) (thread2)
tmp = sum // 10
tmp = sum // 10
tmp += 1 // 11
sum = tmp // 11
tmp = sum // 11
tmp += 1 // 12
tmp += 1 // 11
sum = tmp // 12
sum = tmp // sum = 11
也就是说,出现了程序 “前进几步”,又被 “后退” 的情况:在共享内存中,语句的执行并不是原子 (atomic) 的。
而 -O1 和 -O2 的执行结果又告诉我们:你也许并不知道编译器实际会把你的程序编译成什么。在 -O1 时,gcc 用 rax寄存器表示了 sum 并在循环结束后才一次性写入,因此最终写入了 n; 而 -O2 干脆把整个循环优化成了 sum += n:
void do_sum() {
long tmp = sum;
if (is_O1) {
for (int i = 0; i < n; i++) ;
}
if (is_O2) {
}
tmp += n;
sum = tmp;
}
由于 -O1 优化时 read(sum) 和 write(sum) 的间隔很长,因此数值几乎总是被覆盖;而 -O2 时 read(sum) 和 write(sum) 几乎紧接着发生,因此得到了看似正确的结果,但理论上仍有极小的出错概率:在共享内存中,语句的执行并不严格按照编写的顺序发生。
实现原子性
计算机系统为我们提供了各种同步机制实现并发控制。最典型的就是互斥锁 lock 和 unlock:
lock(&lk); // 临界区, critical section unlock(&lk);能实现 “临界区” 的保护——
lock(&lk)一旦返回,其他任何线程都不能获得lk,直到执行unlock(&lk)为止。同步是操作系统课程中的重要内容。另外值得一提的是,大部分库函数都是线程安全 (看起来是原子) 的 (如
printf),你不必担心多个线程破坏printf的输出。你可以查看printf的 man page 来确认这一点。
2.2. 编译器:顺序的丧失
编译器只考虑程序在一个线程 (处理器) 上执行的顺序语义——如果假设每一个内存访问都可能读到来自其他线程的值、并且这个值是有用的话,几乎就没有编译优化的空间了。经过了几十年的发展,编译优化 (以及静态程序分析) 已经是一个相当成熟、深刻的领域。在这里,我们用一个简化的模型来揭示一下编译优化做了什么,即考虑一个顺序程序只做读内存、写内存和局部本地的计算。
[1] t1 = R(x)
-> t1 = t1 + 1
-> [2] W(x, t1)
-> [3] t2 = R(x)
-> t2 = t2 * 2
-> [4] W(x, t2)
-> [5] t2 = R(y)
首先考虑 [2] -> [3]。容易发现,我们读出的变量,恰好是刚才写入的变量,即对于顺序程序,在 [3] 结束时,我们能证明 $t_2=t_1$。换句话说,我们可以把读操作删除,改写成一个本地的计算:
[1] t1 = R(x)
-> t1 = t1 + 1
-> [2] W(x, t1)
-> t1 = t1 * 2
-> [4] W(x, t1)
-> [5] t2 = R(y)
再考虑 [2] -> [4],连续的两次对 x 的写操作,后一次会覆盖前一次的数值。从顺序执行程序的意义上,把 [2] 删除也不会有任何影响:
[1] t1 = R(x)
-> t1 = t1 + 1
-> t1 = t1 * 2
-> [4] W(x, t1)
-> [5] t2 = R(y)
此外,如果 x 和 y 不是同一个变量 (实际的情况可能复杂一些,例如 x 和 y 可能是由 pointer dereference 得到的,判定它们是否是同一个变量属于 “指针分析” 这一难题),编译器可能出于性能的考虑,交换 [5] 和 [4],得到在处理器意义上可能运行得更快的代码:
[1] t1 = R(x)
-> [5] t2 = R(y) // 使内存访问提前,减少 cache miss 对后续指令的影响
-> t1 = t1 + 1
-> t1 = t1 * 2
-> [4] W(x, t1)
可见,一小段代码已经被优化得完全面目全非了——之前的求和函数不同优化的结果都是合理的,以下都是求和函数在顺序意义上等价的表示:
// 不优化的时候几乎是一个 “忠于 C 代码” 的直接翻译。
void f_O0() {
for (int i = 0; i < N; i++) {
int t = R(sum);
t++;
W(sum, t);
}
}
启动 O1 后,sum 的求和被提出了循环——循环内除了第一次读和最后一次写 sum,都是冗余的,因此第一次读和最后一次写被移动到了循环外面,其他读写都被删除。删除后, 个加一也被合并成一个加 :
void f_O1() {
int t = R(sum);
for (int i = 0; i < N; i++) ;
t += N;
W(sum, t);
}
但有趣的是,在 O1 优化下,循环变量 i 并没有被优化,-O1 不会 “删除” 程序中的任何一个定义的变量,这样既得到优化的结果,又不至于使调试太困难。我们看到输出 的原因是在 R(sum) 和 W(sum) 之间有了一个很长时间的空循环,好像:
void f() {
int t = R(sum);
delay(some_milliseconds);
t += N;
W(sum, t);
}
因为 delay 的存在,两个线程的 R(sum) 几乎总是先发生,并同时读到 0,在 W(sum) 时,同时写入 。
在 O2 优化下,求和的循环被彻底删除了,被优化成了 “最优” 的代码,一次读内存、一次加法、一次写内存。
void f_O2() {
int t = R(sum);
t += N;
W(sum, t);
}
// 一条指令: addq $n, 0x20073d(%rip) # <sum>
此时,f_O2 的执行时间非常短,它们并发的可能性也极低 (但理论上仍可能不正确,且在实际的处理器中能够观测到,因为 add 指令在处理器上的实现并不是原子的),所以我们看到了貌似正确的结果。
实现顺序控制
作为一个系统编程语言,C语言当然为我们提供了相应的设施。一方便可以用
volatile关键字;你能区分以下定义的区别吗:volatile char *p; char * volatile p; volatile char * volatile p;以及,更轻量级的 memory barrier,通过一条空的汇编指令,但假设这条汇编指令会修改任意内存 (clobber memory) 实现:
#define barrier() asm volatile ("":::"memory")可以阻止优化跨越边界:
void foo() { x++; barrier(); x++; }会生成两条独立的
add指令。
2.3. 多核处理器:可见性的丧失
一个更让人费解的例子是:
int volatile x = 0, y = 0;
void thread1() {
[1] x = 1; // write(x)
[2] ty = y; // read(y)
}
void thread2() {
[3] y = 1; // write(y)
[4] tx = x; // read(x)
}
这个程序太简单了,就是写一个变量,读另一个变量嘛 (最后输出 (tx, ty) 的值)。把语句看作指令 (实际上也正是如此编译成指令的) 有以下执行顺序:
- [1] → [2] → [3] → [4], 最后将得到 (0, 1)
- [3] → [4] → [1] → [2], 最后将得到 (1, 0)
- [1] → [3] → [4] → [2], 最后将得到 (1, 1)
- [1] → [3] → [2] → [4], 最后将得到 (1, 1)
- ...
无论如何,第一个执行的指令总是 (1) 或 (2),因此……什么?在实际执行的时候,我压根就没看到过 (1, 1),但是却看到了 (0, 0)?看不到 (1, 1) 还可以接受:这两条指令在 0.000000001s 就执行完了,没来得及切换,但看到 (0, 0) 似乎有些过分了?
思考题 (难):编写怎样的代码重现这个实验?
让
thread1和thread2近乎同时开始执行不是一件很容易的事情。如果你连续调用create(thread1); create(thread2);它们几乎总是先后执行。等到大家学完并发部分,应该能写出重现这个实验结果的代码。
实际上,不仅是编译器可能会改变指令执行的顺序,处理器也会,这会引起处理器之间内存读写可见性的问题。假设一个线程按如下顺序执行指令:
movl $1, x(%rip) // write(x)
movl y(%rip), %eax // read(x)
考虑到内存相对于处理器是非常慢的设备,为了加速内存的访问,现代计算机系统都利用了局部性,在处理器上增加了缓存。因为缓存的速度非常快,无法做到多处理器之间的共享,所以现代多处理器系统里,每个处理器都有自己的缓存 (实际情况会更复杂一些,例如每个处理器有独立的 L1 cache,处理器之间则共享 L2 和 L3):
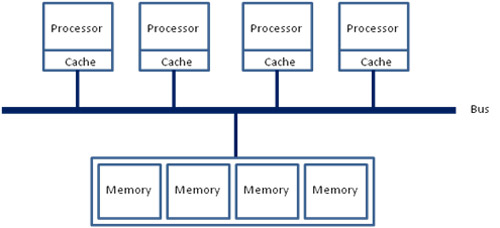
而 cache miss 则是现代处理器性能损失的一大问题:
movl $1, x(%rip) // cache miss
// 巨长无比的等待
movl y(%rip), %eax // read(x)
所以,现代处理器在 cache miss 的时候,不会坐以待毙 (悄悄进入节能模式等待缓存数据),而是立即转去执行下一条指令 (不带停的,乱序执行),甚至上述两条指令,可以在同一个时钟周期开始执行 (多发射)!只要指令之间没有数据依赖关系、分支预测准确,无论是否有 cache miss,处理器都能保持不断开始执行新的指令,cache miss 也不会降低处理器的吞吐量。这就是现代处理器单核心性能增长的终极来源——利用指令级的并行。
但乱序执行带来的麻烦是,可能导致 read/write 的顺序发生变化,从而造成在当前处理器上 “已经发生的写操作在其他处理器不可见”。在刚才的例子里,因为 write 发生了 cache miss,内存访问发生的顺序则是
movl y(%rip), %eax
movl $1, x(%rip)
只要 x 和 y 是不同的变量,从顺序程序的角度,这个顺序调换是没有任何问题的;但对于多处理器来说,就会导致上述例子中那种难以理解的程序执行结果。这导致了程序的执行是 “不可串行化” 的——程序的并发执行结果不等于任何一个指令顺序执行的排序。并发程序执行的行为由内存模型 (memory model) 定义。这个问题的详细探讨 超出了本课程讨论的范围,我们只需知道这种现象存在即可:在多个线程共享内存时,并发程序行为的准确建模是十分困难的。
实现处理器间的可见性
硬件为我们提供了指令 (例如 x86 的 “路障” 指令
SFENCE, LFENCE, MFENCE) 来调控乱序执行处理器上内存访问的行为。此外,处理器还提供了同步指令 (例如 x86 的 lock prefix),使一条有不止一个内存访问的指令能够原子地完成,例如lock addq $1, x(%rip)可以实现原子的
x++。同步指令同时保证了多处理器之间的可见性。同步指令是操作系统实现线程同步的基础,之后我们会详细深入地介绍。
2.4. 结束语:顺序、原子性、可见性都丧失了,我们还编个 JB?
这就是为什么 Ad hoc synchronization considered harmful——作为一个 “程序员” (不是并发算法的专家) 如果 “自作聪明” 想用共享内存来实现并发算法,那犯错误的概率就很大。为了解决并发编程这个老大难问题,计算机系统为我们提供了同时保证顺序、原子性、可见性的同步操作——互斥锁、条件变量、信号量、事务内存……帮助程序员写出正确性容易保证的代码、实现并发控制。在此基础上,编程语言和框架通常还会对并发的使用作出限制,例如 JavaScript 的事件模型、Future 模型、Actor 模型等等。
