共享内存多线程
本讲阅读材料
本讲的阅读材料是本文档 (讲义)。带着 “程序是状态机” 的视角,你不仅可以试着自己画出 Peterson/Dekker/任何算法的状态机,并理解它们能够正确工作的假设和它们正确的原因。“程序 = 计算机系统 = 状态机” 这一理解将贯穿整个《操作系统》课程。
1. 状态机
“状态机” 是对物理世界运行的抽象数学模型。熟悉图论的同学,不妨把状态机看成是有向图 $G(V,E)$,其中:
-
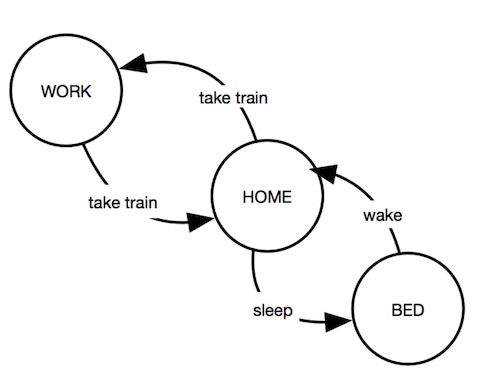
图的每个节点 $s \in V$ 代表一个 “状态”,不同的节点通常代表不同的状态,例如下图是一个 (可怜的、没有娱乐的) 人状态的抽象——他要么在工作,要么在家,要么在床上:
-
图中的边 $(s_1, s_2) \in E$ 代表状态的转换,有时也写作 $s_1 \to s_2$。当状态机系统的外部发生变化时,状态机的状态随之会发生改变,例如当前状态是 “在家”,那么既有可能进入 “床上” 的状态睡觉,也有可能乘地铁上班,进入 “工作” 的状态。
-
图中的边有时有标签 (label),表示系统外界发生的具体变化。
这个概念非常之简单 (甚至 trivial) 以至于你会觉得它有什么用?答案有两点:
- 状态机是物理世界的抽象,几乎任何物理对象都或多或少可以写成状态机。一旦状态机建立,我们就得到了一个图——于是我们可以用图论的算法去研究状态机的性质。例如,当我们写出一个并发程序 (并发算法、并发协议) 的状态机后,就能用图论的语言定义并发程序算法的 “正确性”,并在 $|E|$ 的多项式时间内完成对算法的证明。
- 计算机系统的本质天然是数字逻辑电路实现的状态机,因此状态机模型也可以帮助我们理解计算机系统的方方面面。状态机的视角帮助我们理解处理器设计、程序调试、自动测试等 non-trivial 的计算机系统解决方案。
2. 程序的状态机模型
我们不妨把运行在操作系统上的程序看成是状态机。在现代计算机系统上,程序只需要有代码、数据 (假设只有静态分配的数据;动态分配数据需要调用操作系统)、堆栈和寄存器,程序就按固定的规则执行:
- CPU 根据当前的 PC 指针 (例如 x86-64 的
rip寄存器),在内存中取出一条指令; - 对指令进行译码、执行,指令将按照手册上约定的行为,修改 CPU 的寄存器或内存。
在《计算机系统基础》的编程实验中,我们已经切实地体会过这个过程。而在 gdb 中,我们也可以查看 (被暂停的) 进程运行时的状态:
(gdb) info registers // 查看寄存器
rax 0x55555555463a 93824992233018
rbx 0x0 0
...
rip 0x55555555463e 0x55555555463e <main+4>
eflags 0x246 [ PF ZF IF ]
...
(gdb) x/16i 0x55555555463e // 查看内存
=> 0x55555555463e <main+4> : lea 0x9f(%rip),%rdi # 0x5555555546e4
0x555555554645 <main+11>: callq 0x555555554510 <puts@plt>
0x55555555464a <main+16>: mov $0x0,%eax
0x55555555464f <main+21>: pop %rbp
0x555555554650 <main+22>: retq
...
如果使用单步执行一条指令,我们将会看到状态的变化,而且状态的变化符合是 rip 寄存器位置指令的行为。因此,我们不妨把所有的寄存器/内存的数值作为程序的状态,程序在两个时刻寄存器/内存数值只要有任何不同,就认为是两个不同的状态。
程序每执行一条指令,状态就会发生变化 (指令执行的结果)。我们用 $(M,R)$ 来表示程序的状态,其中 $M$ 是程序所有内存的数值;$R$ 是程序所有寄存器的数值。例如,假设 $M[R[\textrm{rip}]]$ 的字节序列是 48 c7 c0 01 00 00 00,即 movl $1, %rax。那么,执行这条指令后程序的状态是 $(M',R')$,则有:
$R'[\textrm{rip}] = R[\textrm{rip}] + 7$ (下一条指令位于 7 个字节之后), $R'[\textrm{rax}] = 1$ (rax 寄存器被设置为 1)
考虑程序一共使用 16 MiB 的内存,有 18 个 64-bit 寄存器,这些状态一共有 $16 \cdot 2^{20} \cdot 8 + 18 \cdot 64 = 134,218,880$ bits。因此,这个程序至多有 $2^{134,218,880}$ 种不同的状态。这是个天文数字——试图把程序所有状态构成的状态机建立出来是完全不切实际的。但这不妨碍我们用状态机模型理解程序的执行。
2.1. 确定 (deterministic) 和不确定 (non-deterministic) 的指令
大部分指令在给定执行前的状态时,执行的结果就是确定的,例如 push, mov 都是这样确定的指令。如果 $(M,R)$ 状态下 PC 指针位置的指令是确定的指令,那么 $(M,R)$ 就拥有唯一的后续状态——事实上,程序执行中绝大部分指令都是确定的,因此程序对应的状态机就像是下图这样:

如果做一个极端一些的假设,程序中所有的指令都是确定的,且由于状态空间是有限的,因此一定会形成 “循环”,即指令执行一段时间后,会到达一个已经经过的状态,然后继续周而复始执行。的确如此,你可以试着编写一个没有不确定性指令、没有系统调用、没有 undefined behavior 的程序,它将无法终止!
程序的不确定性的一个来源是 “不确定”的指令,例如,Intel 处理器提供了 rdrand 指令:
#include <stdio.h>
#include <stdint.h>
int main() {
uint64_t val;
asm volatile ("rdrand %0": "=r"(val));
printf("rdrand returns %016lx\n", val);
}
将会生成一条 rdrand %rax 的汇编代码。如果用 gdb 调试,会发现每次程序运行,rax 寄存器都将被赋值为随机值,也就是在 rdrand 指令执行的状态,可能有多种不同的运行结果,状态机也在此产生了 $2^{64}$ 个 “分岔”:
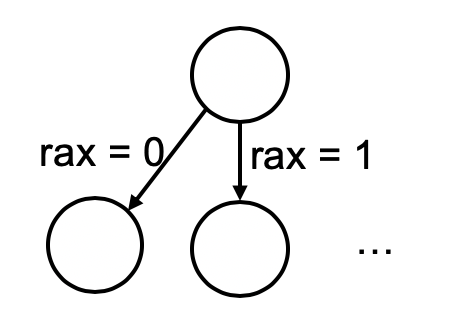
另一个重要的不确定性指令是系统调用 (例如在 x86-64 上是 syscall 指令)。例如,_exit 系统调用将会销毁当前进程的执行,相当于从外界把状态机 “消灭”,进入一个 “不存在” 的状态。再比如 read 系统调用:
- 根据读入流的情况,有可能返回 -1 (失败)、0 (end of file)、某个正数代表读取的字节数;
read传入的buf可能会被操作系统修改为读取到的数据。
因此,根据当前调用 read 时物理设备、操作系统等的状态,read 系统调用可能的后续状态就更多了。
上面这个模型称为 “Simple Sequential Execution” (SSE),这对于我们理解计算机系统的执行是非常有帮助的——在我们的 NEMU PA 实验中,我们就模拟实现了你选择的指令集体系结构的 SSE 语义 (相当于 “抄了” 一遍手册)。
2.2. 并发程序的状态机模型
在课堂上,我们反复演示 (和强调) 并发程序的多个线程拥有独立的寄存器、堆栈 (但不同线程的堆栈位于同一个地址空间中,我们已经在课堂上展示过),共享代码和数据。因此并发程序的状态表示是刚才我们提到 $(M, R)$ 模型的一个自然扩展:系统中仍然有一份共享的内存,但每个线程都有独立的寄存器。因此假设系统中有 $n$ 个线程,那么状态看起来就是:
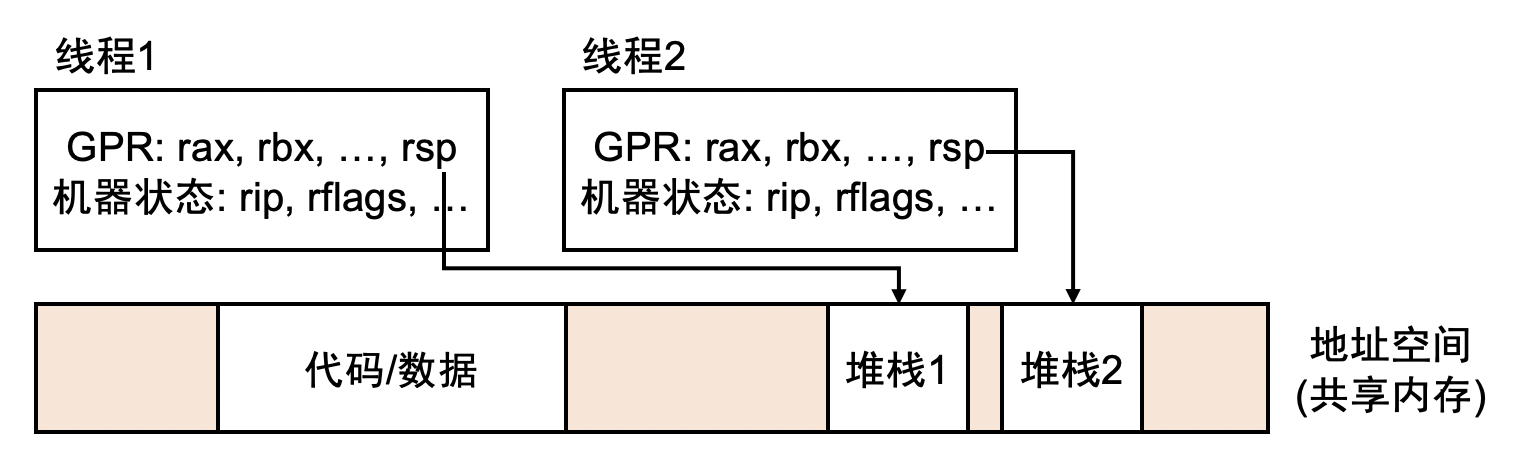
注意到多线程程序 $(M, R_1, R_2, \ldots, R_n)$ 其实可以看成是若干个单线程程序。在任意时刻,状态的转换就是 “选择一个线程执行一条指令”:
- 选择线程 $1$ 执行:$(M, R_1) \to (M_1', R_1')$,得到状态 $(M_1', R_1', R_2, \ldots, R_n)$;
- 选择线程 $2$ 执行:$(M, R_2) \to (M_2', R_2')$,得到状态 $(M_2', R_1, R_2', \ldots, R_n)$;
- $\ldots$
- 选择线程 $n$ 执行:$(M, R_n) \to (M_n', R_n')$,得到状态 $(M_n', R_1, R_2, \ldots, R_n')$;
也就是说,并发程序执行的每一步都是不确定的!并发程序的状态机模型如下图所示:
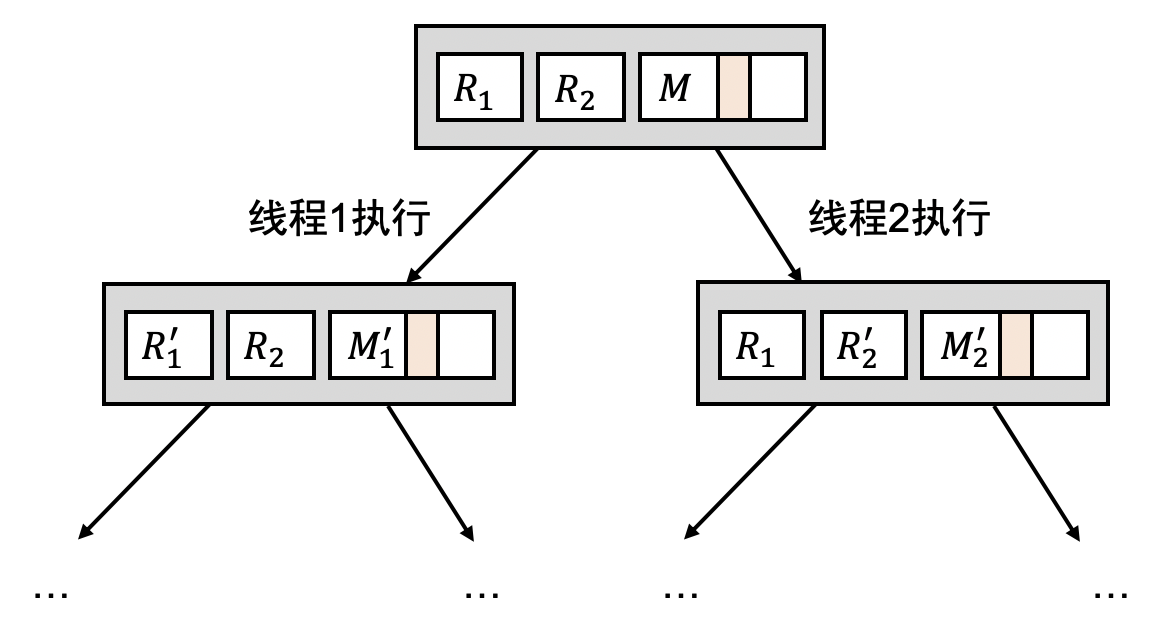
想要在实际的多线程程序上验证这个模型,我们不妨使用 pmap 命令打印一个多线程程序的地址空间映射:
$ ./hello-mt.out &
[1] 18401
$ pmap $! # $! 是上一个后台进程的 pid
18401: ./hello-mt.out
00005629379d2000 4K r-x-- hello-mt.out
0000562937bd2000 4K r---- hello-mt.out
0000562937bd3000 4K rw--- hello-mt.out
00005629387e7000 132K rw--- [ anon ]
00007fde98000000 132K rw--- [ anon ]
00007fde98021000 65404K ----- [ anon ]
00007fde9dd7c000 4K ----- [ anon ]
00007fde9dd7d000 8192K rw--- [ anon ]
00007fde9e57d000 4K ----- [ anon ]
00007fde9e57e000 8192K rw--- [ anon ]
如果在每个线程打印局部变量的地址,机会发现局部变量的确位于不同的 8192 KiB 内存映射区域,即我们假想的状态机模型的确符合操作系统上线程的实现。
动手实践
你可以试一试打印多线程程序每个线程局部变量的地址,并和
pmap的结果对比,这将加深你对这个问题的认识,除此之外,在操作系统上实际编写一些程序,也能让你遇到一些只是学习理论未必会遇到的 “坑”,进一步增进你的理解——经验的积累使你的系统能力不断增长,不知不觉就会成为这一方面的专家。
事实上,将线程的堆栈放置在同一个地址空间中,在实现上既比较容易,同时对 C 程序的执行也是非常必要的,例如我们可以写出以下代码:
int *shared;
void thread1() {
int x;
...
shared = &x; // 局部变量的地址
...
}
void thread2() {
...
*shared = 1; // 向另一个线程的堆栈中写入输入;
// 只要 `thread1()` 不返回,这个写入就是合法的
...
}
这个模型帮我们更好地理解了什么是 “多线程程序”。所谓 “多线程程序是若干个共享内存的执行流”,不再是一个抽象、虚幻的概念,而是可以形式化地精确定义行为的数学对象。
$n$ 个线程的并发程序,若每个线程执行 $m$ 条指令,就算所有指令都是确定的,不同的执行顺序也多达 $n^{O(mn)}$,这根本就是个天文数字,也难怪并发程序的执行难理解了——冷不丁的犄角旮旯里就藏着并发的 bug。
2.3. 理解并发程序的执行
并发程序的状态机模型把并发程序的理解问题转换成了图论问题。在这里,我们举的是 Peterson 算法的例子——互联网上有大量的解释,因此我们在这里不再赘述。请大家跟随上课视频,画出 Peterson 算法的状态机,并证明它的正确性:
int turn, x = 0, y = 0;
void thread1() {
[1] x = 1;
[2] turn = T2;
[3] while (y && turn == T2) ;
[4] // critical section
[5] x = 0;
}
void thread2() {
[1] y = 1;
[2] turn = T1;
[3] while (x && turn == T1) ;
[4] // critical section
[5] y = 0;
}
思考题:为什么多此一举?
Peterson 算法中有三个变量,对应了现实中 $T_1$ 的旗子、$T_2$ 的旗子和一块牌子。这似乎是必不可少的——你可以试试如果只用旗子的互斥,例如:
void thread1() { x = 1; while (y); } void thread2() { y = 1; while (x); }上述代码将在两个人同时举旗之后陷入僵局。当然,你可以试着把旗子在举起后,如果观察到对方也举起旗子,就把自己的旗子放下:
void thread1() { retry: x = 1; if (y) x = 0; if (!x) goto retry; } void thread2() { retry: y = 1; if (x) y = 0; if (!y) goto retry; }但这将可能会陷入 “举起-放下” 的无限循环……(但其实这个算法已经足够好了)。
在共享内存上 (假设指令可以每次原子性地读取/写入一个变量) 实现线程的互斥困扰了学术界很多年,并在此基础上发展出了非常深刻的研究分支。有兴趣的同学可以选修秋季学期的《并发算法与理论》课程。
Peterson 算法 (以及其他并发算法) 的正确性分为两个部分:
2.3.1: 证明坏事永远不会发生 (Safety)
对 Peterson 算法来说,两个线程绝对不能同时进入临界区。线程进入临界区,意味着 $T_1$ 或 $T_2$ 进入了 $\textrm{PC}=4$ 的状态。所以 Peterson 算法满足 safety 的另一种表达是 “在任意程序的执行中,$\textrm{PC}_1 = 4 \land \textrm{PC}_2 = 4$ 不会出现”。
于是,对于任意的一个状态 $s = (M, R_1, R_2)$,我们都可以知道它是不是一个 “违反了 safety 的状态” (只需检查 $\textrm{PC}$ 即可)。从而,从初始状态出发,如果存在某个线程调度能达到一个 “坏” 的节点,我们就证明算法错了;否则算法就是正确的。
图论的语言和算法
把状态机看成是有向图 $G$,$G$ 满足 safety 当且仅当 $\textrm{PC}_1 = 3 \land \textrm{PC}_2 = 3$ 的节点在 $G$ 上不可达。假设我们已经构造了 $G$,这就图论中很基本的连通性问题 (通常是算法书上图论部分介绍的第一个算法),使用 dfs/bfs 可以轻松解决。
2.3.2: 证明好事永远会发生 (Liveness)
“好事总会发生” 的定义稍稍困难一些。我们将它表达为,“如果给两个线程足够的时间,一定至少有一个能进入临界区”,即到达 $\textrm{PC}_1 = 4 \lor \textrm{PC}_2 = 4$。
Liveness 定义的困难之处在于,我们要给 “两个线程足够的时间”。只给一个线程足够的时间是不够的——它自己可能无限循环,但只要让它和另一个线程交替执行几步,就可以进入临界区。
图论的语言和算法
把状态机看成是有向图 $G$,$G$ 满足 liveness 当且仅当不存在 $G$ 的一条 (无穷) 路径,在该路径上每个线程都执行了无穷多步,且所有经过的节点无一进入临界区 ($\textrm{PC}_1 \ne 4 \land \textrm{PC}_2 \ne 4$)。
“不存在” 性的证明通常求解它的反面:即我们只要求出一条不满足 liveness 的无穷路径,就能证明 liveness 被违反了。无穷路径怎么求呢?这里用一点算法上的小 trick:
- 一条无穷长的路径、$T_1$, $T_2$ 都出现了无穷多次,当且仅当 $T_1$, $T_2$ 交替出现无穷多次。
换句话说,只要存在某个状态 $s$,从 $s$ 出发标有 $T_1$ 和 $T_2$ 的状态转换能够在有限步之内互相可达并回到 $s$ (且不进入临界区),且从初始状态 $s_0$ 到 $s$ 可以不进入临界区,我们就找到了一条满足条件的无穷路径。这可以用大家在图论中学过的 “强连通分量” 算法求解——这就是 Büchi Automata 的验证算法的核心之一。
“程序就是状态机” 是一个非常强大的工具,能够帮助我们理解程序的执行,这也是操作系统课程上所用为数不多的理论工具之一。
3. 实现一个 Model Checker
上述用图论的方法 “prove by brute-force” 在大家实际操作起来一定会遇到不小的麻烦——程序的执行非常 tedious,只要有一个地方有细微的小错,证明就可能不成立 (漏掉了可能出错的状态;或是得到了某个不可达的状态)。不过大家作为程序员,也立即会敏锐地发现:
3.1. 设计 Model Checker
没错,我们完全可以实现一个计算机程序 (Life is short, use python!) 来自动帮我们检查任何并发程序的正确性,例如在课堂上给出的参考 model checker 中,我们支持定义初始状态 (变量和它们的初值):
_init:
x: 0
y: 0
turn: X
此外,我们需要给出每个线程执行的指令序列,其中每条指令 (每一行) 都必须是一行合法的 Python 代码,并且只能访问初始状态中定义过的变量 (对于每个线程的局部变量,我们可以在初始状态中定义每个线程的副本,例如 tmp_0, tmp_1)。此外,我们希望每一行代码都代表最小的 “一步” 执行,因此不能使用循环等复杂的结构。为了方便描述任何程序,我们在 Python 代码的基础上提供了额外的一个函数 GOTO,可以跳转到某条指令执行。
T1: |
x = 1
turn = 'T2'
if y != 1: GOTO(4)
if turn == 'T2': GOTO(2)
x = 0
GOTO(0)
T2: |
y = 1
turn = 'T1'
if x != 1: GOTO(4)
if turn == 'T1': GOTO(2)
y = 0
GOTO(0)
帮助我们检查正确性时,我们支持使用 Python 代码描述标记的条件。这里可以使用 PC: dict,可以从线程名中取出当前执行指令的位置。
_bug_on: |
PC['T1'] == 4 and PC['T2'] == 4 # 在两个线程同时进入临界区时标记错误
_mark_on: |
PC['T1'] == 4 or PC['T2'] == 4 # 在至少有一个线程进入临界区时标记提醒
3.2. 实现 Model Checker
大家可能感到意外,model checker 的实现异常简单,它的核心是一个大家熟悉的 breadth-first search 的循环,再熟悉不过的代码:从队列中取出头部的元素,然后枚举线程、执行一步 (expand),如果得到的状态未被访问过,就添加到队列中。最后我们得到 nodes 和 edges 组成的状态图:
queue, explored, nodes, edges = [ s0 ], { H(s0) }, [ s0 ], []
while queue:
s, queue = queue[0], queue[1:]
for t in threads:
s1 = expand(s, t)
if H(s1) not in explored:
nodes.append(s1)
queue.append(s1)
explored.add(H(s1))
edges.append((H(s), H(s1), t))
Model checker 实现中第一个有趣的 hack 是我们对代码的预处理。Python 中并没有 GOTO——我们是如何表达线程状态 (PC) 的变化的呢?短短几行的程序:
def parse(code):
for line in code.strip().splitlines():
yield re.sub(r'GOTO\((.*?)\)', r'pc = \1 - 1', line.strip() + '\npc += 1')
会把 GOTO(x) 替换成 pc = x - 1,并且在每条指令之后都增加一行 pc += 1。所以,我们的指令序列,例如 Peterson 算法中的 turn = 'T2' 会被替换为
turn = 'T2'
pc += 1
而 if y != 1: GOTO(4) 则会被替换为
if y != 1: pc = 4 - 1
pc += 1 # 因为 pc += 1 是每次都添加的,所以 GOTO 的目标减去了 1
在此基础上,我们又用了 Python 可以在运行时执行任意代码的特性,实现了非常简洁的 expand:
def expand(s, t):
pc = s['PC'][t]
stmt = P[t][pc]
s1 = { **s, 'PC': s['PC'].copy(), 'pc': pc }
exec(stmt, {}, s1) # hah! we're cheating!
s1['PC'][t] = s1['pc']
return { k: s1[k] for k in variables }
在状态 s 中,除了包含变量的值 (x, y, turn) 之外,还有 PC 保存了每个线程的执行位置。我们首先把当前执行线程的 PC 提取到 pc 变量中 (pc = s['PC'][t]),然后执行代码,最后把 pc 写回到 s1['PC'][t] 中,就完成了一步状态的扩展。
大家可以自由修改 model checker 的代码,以使它们的使用更顺手,例如我们可以仅在发现新节点时才加入边到 edges,从而能得到树结构的状态,更易于阅读:
4. 延伸阅读
我们在上课时,介绍了如何用状态机模型理解 time-travel debugging 和 record & replay。这两个计算机系统领域的 “黑科技” 在状态机意义下的解释非常清楚明确:
- 给一次程序的执行 ($s_0 \to s_1 \to\ldots$),如果记录下所有的状态 $s_i$,我们自然可以随时查看 $s_i$ 的状态,从而实现 “时间旅行”。但这样记录状态的代价太大了——当然,我们知道通常 $s_0$ 的状态是容易记录的;由于每条指令的执行通常只影响数量很少的寄存器和内存,我们可以记录 $s_i$ 和 $s_{i+1}$ 之间 “不同” 的部分,就像 diff,我们就可以像给程序 “打补丁” 一样自由地向前或向后执行。
-
如果我们对 “时间穿梭” 没有兴趣,只是想重现一次程序执行的结果。假设所有指令都是确定的,那么只要记录下 $s_0$,无论执行多少次,都必然得到完全相同的执行结果。对于应用程序来说,产生不确定性的指令数量是很少的 (rdrand, syscall 等)。因此,只需要在这些指令之后记录下指令带来的不确定后果,例如:
- 对于 rdrand,记录下得到的随机数值;
- 对于 syscall,记录下系统调用返回的结果,例如
read需要记录它的返回值和读到的数据。
然后,我们只要在重放 (replay) 时,遇到这些不确定的指令时不实际执行,而是用记录下的结果替代,就能实现程序行为的精准重放。同理,也可以实现整虚拟机完整执行的记录和重放。事实上,很多游戏模拟器就内置了这样的记录功能。有兴趣的同学可以阅读推荐的论文:
- George W. Dunlap, Samuel T. King, Sukru Cinar, Murtaza A. Basrai, Peter M. Chen. ReVirt: Enabling intrusion analysis through virtual-machine logging and replay. In Proc. of OSDI, 2002.
在有了状态机的视角之后,我们就有了具体实现这些技术的切入点。例如,如果我们希望在调试器上实现 time-travel debugging,我们只需要在单步模式下分析当前 PC 指针下的指令,解析出该指令所有可能产生的副作用,并予以记录——事实上,gdb 的确就是这么实现的。
再例如,如果我们要实现 record & replay,一个重要的问题是如何 “拦截” 那些具有不确定性的指令。通过查阅资料 (互联网、论文、文档),我们一方面可以使用 ptrace 系统调用,或使用编译器提供的接口拦截指定的函数调用,另一方面也可以通过修改程序的二进制代码 (例如像 gdb 一样给有不确定性的指令打补丁),使有不确定性的指令执行时跳转到指定位置的代码。
计算机系统里没有什么 “魔法”——计算机系统就是一个状态机。哪怕是最顶尖的研究成果,也是在这个框架下完成的,例如从状态机上的一次执行 (即测试输入决定的一条路径) 出发,通过改变一个分支的方向 (并保持之前的分支不变),以求解出更多的测试用例覆盖更多的代码。
- Cristian Cadar, Daniel Dunbar, Dawson R. Engler. KLEE: Unassisted and automatic generation of high-coverage tests for complex systems programs. In Proc. of OSDI, 2008.
在 trivial model checker 中,我们使用了队列和集合来存储探索过的程序状态——这种技术称为 “stateful” 的 model checking。但你一定也好奇:如果我们想 model check 实际中的程序,而程序中有太多的变量,如果直接将它们放在状态中,那状态空间就太复杂,算法肯定执行不完了。是否有可能像 “走迷宫” 那样,不记录走过的状态,但又可以有效地探索状态空间?
- Patrice Godefroid. Model checking for programming languages using VeriSoft. In Proc. of POPL, 1997.
最后给大家一个思考题:是否能在在并发程序上实现 time-travel debugging 或 record and replay?因为并发多线程的调度 (指令的执行顺序) 是重要的不确定性来源,因此想要再时间上回溯或是重放执行,就必须把因线程调度导致的不确定性记录下来——例如,记录所有共享内存访问的顺序。这是一个非常有挑战性的问题,jyy 的博士论文就在这方面做了一些理论和实际的工作——甚至提出了一个有些悲观的猜想 (做了部分情况的证明):在没有硬件机制的帮助下,如果想观测/记录并发程序的执行,我们要么不可避免地在程序里增加同步操作,要么就要在重放时付出 NP-Completeness 的代价。

{kind=link}