Overview
复习
- 并发编程的基本工具:线程库、互斥和同步
- 并发编程的应用场景:高性能计算、数据中心、网页/移动应用
本次课回答的问题
- Q: 并发编程那么难,我写出 bug 怎么办?
本次课主要内容
- 应对 bug (和并发 bug) 的方法
- 死锁和数据竞争
应对 Bug 的方法
基本思路:否定你自己
虽然不太愿意承认,但
始终假设自己的代码是错的 。
然后呢?
- 做好测试
- 检查哪里错了
- 再检查哪里错了
- 再再检查哪里错了
- (把任何你认为 “不对” 的情况都检查一遍)
Bug 多的根本原因:编程语言的缺陷
软件是需求 (规约) 在计算机数字世界的投影。
只管 “翻译” 代码,不管和实际需求 (规约) 是否匹配
- alipay.c 的例子
- 变量
balance代表 “余额” - 怎么看 withdraw 以后 0 → 18446744073709551516 都不对
- 变量
三十年后的编程语言和编程方法?
- Annotation verifier (Dafny)
- Specification mining (Daikon)
- Refinement types
- Program sketching……

防御性编程和规约给我们的启发
你知道很多变量的
#define CHECK_INT(x, cond) \
({ panic_on(!((x) cond), "int check fail: " #x " " #cond); })
#define CHECK_HEAP(ptr) \
({ panic_on(!IN_RANGE((ptr), heap)); })
变量有 “typed annotation”
CHECK_INT(waitlist->count, >= 0);CHECK_INT(pid, < MAX_PROCS);CHECK_HEAP(ctx->rip); CHECK_HEAP(ctx->cr3);- 变量含义改变 → 发生奇怪问题 (overflow, memory error, ...)
不要小看这些检查 ,它们在底层编程 (M2, L1, ...) 时非常常见- 在虚拟机神秘重启/卡住/...前发出警报
并发 Bug:死锁 (Deadlock)
死锁 (Deadlock)
A deadlock is a state in which each member of a group is waiting for another member, including itself, to take action.
出现线程 “互相等待” 的情况

AA-Deadlock
假设你的 spinlock 不小心发生了中断
- 在不该打开中断的时候开了中断
- 在不该切换的时候执行了
yield()
void os_run() {
spin_lock(&list_lock);
spin_lock(&xxx);
spin_unlock(&xxx); // ---------+
} // |
// |
void on_interrupt() { // |
spin_lock(&list_lock); // <--+
spin_unlock(&list_lock);
}
ABBA-Deadlock
void swap(int i, int j) {
spin_lock(&lock[i]);
spin_lock(&lock[j]);
arr[i] = NULL;
arr[j] = arr[i];
spin_unlock(&lock[j]);
spin_unlock(&lock[i]);
}
上锁的顺序很重要……
swap本身看起来没有问题swap(1, 2);swap(2, 3),swap(3, 1)→ 死锁- philosopher.c
避免死锁
死锁产生的四个必要条件 (Edward G. Coffman, 1971):
- 互斥:一个资源每次只能被一个进程使用
- 请求与保持:一个进程请求资阻塞时,不释放已获得的资源
- 不剥夺:进程已获得的资源不能强行剥夺
- 循环等待:若干进程之间形成头尾相接的循环等待资源关系
“理解了死锁的原因,尤其是产生死锁的四个必要条件,就可以最大可能地避免、预防和解除死锁。所以,在系统设计、进程调度等方面注意如何不让这四个必要条件成立,如何确定资源的合理分配算法,避免进程永久占据系统资源。此外,也要防止进程在处于等待状态的情况下占用资源。因此,对资源的分配要给予合理的规划。” ——
Bullshit .
避免死锁 (cont'd)
AA-Deadlock
- AA 型的死锁容易检测,及早报告,及早修复
- spinlock-xv6.c 中的各种防御性编程
if (holding(lk)) panic();
ABBA-Deadlock
- 任意时刻系统中的锁都是有限的
- 严格按照固定的顺序获得所有锁 (lock ordering; 消除 “循环等待”)
- 遇事不决可视化:lock-ordering.py
- 进而证明 $T_1: A\to B\to C; T_2: B \to C$ 是安全的
- “在任意时刻总是有获得 “最靠后” 锁的可以继续执行”
Lock Ordering: 应用 (Linux Kernel: rmap.c)

但是……你又 Naive 了……
Textbooks will tell you that if you always lock in the same order, you will never get this kind of deadlock.
The best locks are encapsulated: they never get exposed in headers, and are never held around calls to non-trivial functions outside the same file. You can read through this code and see that it will never deadlock, because it never tries to grab another lock while it has that one. People using your code don't even need to know you are using a lock.
—— Unreliable Guide to Locking by Rusty Russell
- 我们稍后回到这个问题,继续看更多的 bugs
并发 Bug:数据竞争 (Data Race)
不上锁不就没有死锁了吗?
数据竞争
不同的线程 同时访问同一段内存 ,且至少有一个是写 。
- 两个内存访问在 “赛跑”,“跑赢” 的操作先执行
- peterson-barrier.c: 内存访问都在赛跑
- MFENCE:
如何留下最少的 fence,依然保证算法正确?
- MFENCE:
- peterson-barrier.c: 内存访问都在赛跑

数据竞争 (cont'd)
Peterson 算法告诉大家:
你们写不对无锁的并发程序 - 所以事情反而简单了
用互斥锁保护好共享数据
消灭一切数据竞争
数据竞争:例子
以下代码概括了你们遇到数据竞争的大部分情况
- 不要笑,你们的 bug 几乎都是这两种情况的变种
// Case #1: 上错了锁
void thread1() { spin_lock(&lk1); sum++; spin_unlock(&lk1); }
void thread2() { spin_lock(&lk2); sum++; spin_unlock(&lk2); }
// Case #2: 忘记上锁
void thread1() { spin_lock(&lk1); sum++; spin_unlock(&lk1); }
void thread2() { sum++; }
更多类型的并发 Bug
程序员:花式犯错
回顾我们实现并发控制的工具
- 互斥锁 (lock/unlock) - 原子性
- 条件变量 (wait/signal) - 同步
忘记上锁——原子性违反 (Atomicity Violation, AV)
忘记同步——顺序违反 (Order Violation, OV)
Empirical study: 在 105 个并发 bug 中 (non-deadlock/deadlock)
- MySQL (14/9), Apache (13/4), Mozilla (41/16), OpenOffice (6/2)
97% 的非死锁并发 bug 都是 AV 或 OV 。
原子性违反 (AV)
“ABA”
- 我以为一段代码没啥事呢,但被人强势插入了

原子性违反 (cont'd)
有时候上锁也不解决问题
- “TOCTTOU” - time of check to time of use
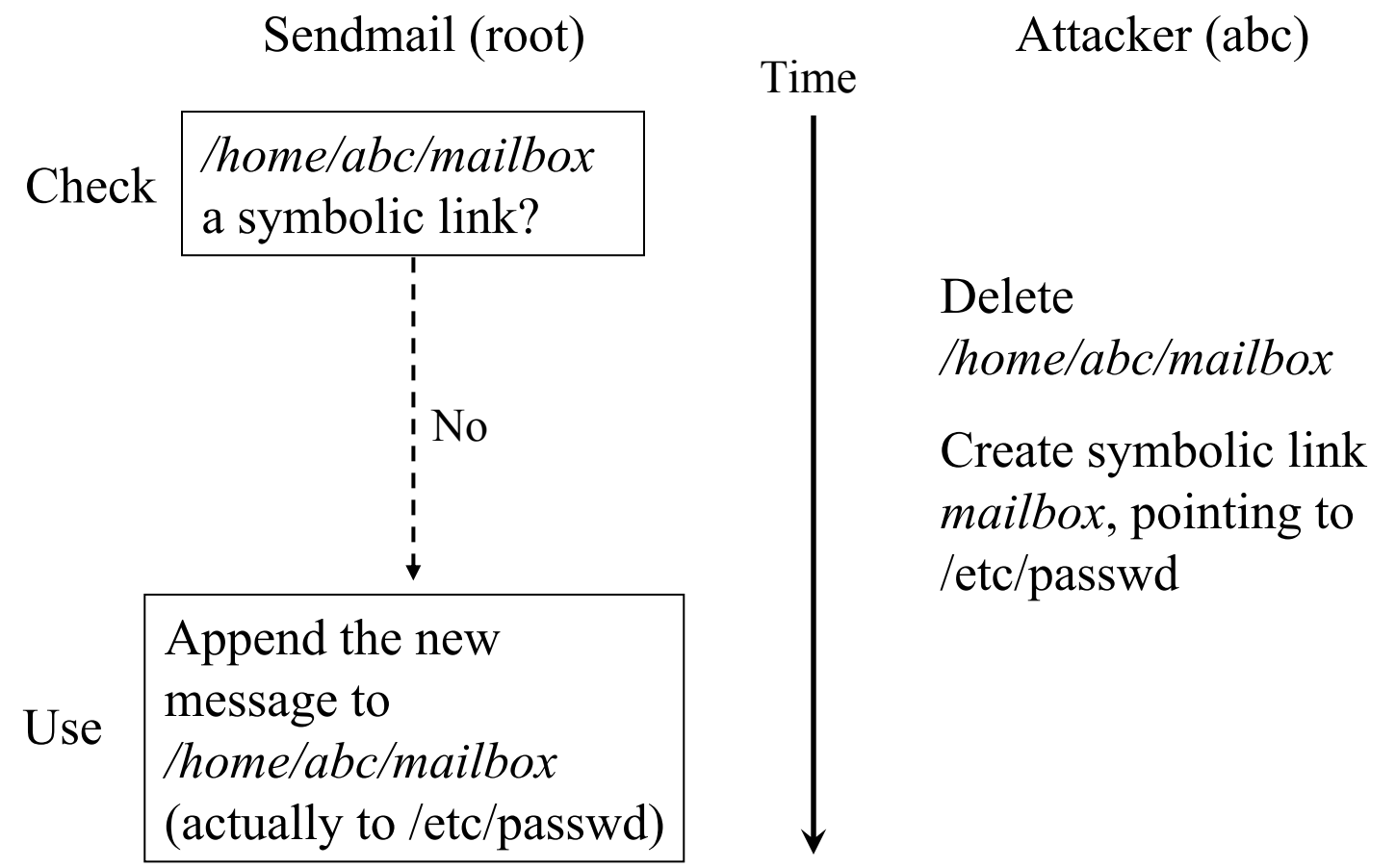
顺序违反 (OV)
“BA”
- 怎么就没按我预想的顺序来呢?
- 例子:concurrent use after free

应对并发 Bug 的方法
完全一样的基本思路:否定你自己
还是得
始终假设自己的代码是错的 。
然后呢?
- 做好测试
- 检查哪里错了
- 再检查哪里错了
- 再再检查哪里错了
- (把任何你认为 “不对” 的情况都检查一遍)
例如:用 lock ordering 彻底避免死锁?
- 你想多了:并发那么复杂,程序员哪能充分测试啊
Lockdep: 运行时的死锁检查
Lockdep 规约 (Specification)
- 为每一个锁确定唯一的 “allocation site”
- lock-site.c
- assert: 同一个 allocation site 的锁存在全局唯一的上锁顺序
检查方法:printf
- 记录所有观察到的上锁顺序,例如 $$[x, y, z] \Rightarrow x \to y, x \to z, y \to z$$
- 检查是否存在 $x \rightsquigarrow y \land y \rightsquigarrow x$
- Since Linux Kernel 2.6.17, also in OpenHarmony!
ThreadSanitizer: 运行时的数据竞争检查
为所有事件建立 happens-before 关系图
- Program-order + release-acquire
- 对于发生在不同线程且至少有一个是写的 $x,y$ 检查 $$x \prec y \lor y \prec x$$
更多的检查:动态程序分析
在事件发生时记录
- Lockdep: lock/unlock
- ThreadSanitizer: 内存访问 + lock/unlock
解析记录检查问题
- Lockdep: $x \rightsquigarrow y \land y \rightsquigarrow x$
- ThreadSanitizer: $x \not\prec y \land y \not\prec x$
付出的代价和权衡
- 程序执行变慢
- 但更容易找到 bug (因此在测试环境中常用)
动态分析工具:Sanitizers
没用过 lint/sanitizers?
- AddressSanitizer (asan); (paper): 非法内存访问
- ThreadSanitizer (tsan): 数据竞争
- Demo: fish.c, sum.c, peterson-barrier.c; ktsan
- MemorySanitizer (msan): 未初始化的读取
- UBSanitizer (ubsan): undefined behavior
- Misaligned pointer, signed integer overflow, ...
- Kernel 会带着
-fwrapv编译
这不就是防御性编程吗?
只不过不需要我亲自动手把代码改得乱七八糟了……
我们也可以!Buffer Overrun 检查
Canary (金丝雀) 对一氧化碳非常敏感
- 用生命预警矿井下的瓦斯泄露 (since 1911)

计算机系统中的 canary
- “牺牲” 一些内存单元,来预警 memory error 的发生
- (程序运行时没有动物受到实质的伤害)
Canary 的例子:保护栈空间 (M2/L2)
#define MAGIC 0x55555555
#define BOTTOM (STK_SZ / sizeof(u32) - 1)
struct stack { char data[STK_SZ]; };
void canary_init(struct stack *s) {
u32 *ptr = (u32 *)s;
for (int i = 0; i < CANARY_SZ; i++)
ptr[BOTTOM - i] = ptr[i] = MAGIC;
}
void canary_check(struct stack *s) {
u32 *ptr = (u32 *)s;
for (int i = 0; i < CANARY_SZ; i++) {
panic_on(ptr[BOTTOM - i] != MAGIC, "underflow");
panic_on(ptr[i] != MAGIC, "overflow");
}
}
烫烫烫、屯屯屯和葺葺葺

msvc 中 debug mode 的 guard/fence/canary
- 未初始化栈:
0xcccccccc - 未初始化堆:
0xcdcdcdcd - 对象头尾:
0xfdfdfdfd - 已回收内存:
0xdddddddd
(b'\xcc' * 80).decode('gb2312')
手持两把锟斤拷,口中疾呼烫烫烫
脚踏千朵屯屯屯,笑看万物锘锘锘
(它们一直在无形中保护你)
防御性编程:低配版 Lockdep
不必大费周章记录什么上锁顺序
- 统计当前的 spin count
- 如果超过某个明显不正常的数值 (1,000,000,000) 就报告
int spin_cnt = 0;
while (xchg(&locked, 1)) {
if (spin_cnt++ > SPIN_LIMIT) {
printf("Too many spin @ %s:%d\n", __FILE__, __LINE__);
}
}
- 配合调试器和线程 backtrace 一秒诊断死锁
防御性编程:低配版 Sanitizer (L1)
内存分配要求:已分配内存 $S = [\ell_0, r_0) \cup [\ell_1, r_1) \cup \ldots$
- kalloc($s$) 返回的 $[\ell, r)$ 必须满足 $[\ell, r) \cap S = \varnothing$
- thread-local allocation + 并发的 free 还蛮容易弄错的
// allocation
for (int i = 0; (i + 1) * sizeof(u32) <= size; i++) {
panic_on(((u32 *)ptr)[i] == MAGIC, "double-allocation");
arr[i] = MAGIC;
}
// free
for (int i = 0; (i + 1) * sizeof(u32) <= alloc_size(ptr); i++) {
panic_on(((u32 *)ptr)[i] == 0, "double-free");
arr[i] = 0;
}
总结
总结
本次课回答的问题
- Q: 如何拯救人类不擅长的并发编程?
Take-away message
- 常见的并发 bug
- 死锁、数据竞争、原子性/顺序违反
- 不要盲目相信自己:检查、检查、检查
- 防御性编程:检查
- 动态分析:打印 + 检查