课程总结
1. 我们学了个啥?
1.1. Introduction
RISC-V 处理器模拟器
C 语言实现的 single-header RISC-V32IMA 系统模拟器 (项目源自mini-rv32ima)。因为有 M-Mode,这个模拟器可以运行几乎 “任意复杂” 的程序——甚至是没有 MMU 的 Linux。我们稍稍修改了这份代码,更好地体现《操作系统》课程的教学目标。
汉诺塔
汉诺塔是递归和分治的经典问题,而同学们也曾经在理解这个程序的时候遇到困难。遇到困难是正常的:C/C++ 中的 “函数” 和数学的函数很不一样,例如我们可以把 Fibonacci 数列的递归写成
int x = f(n - 1);
int y = f(n - 2);
// 也可以 return y + x;
return x + y;
或是任意调换函数调用的次序,但汉诺塔不行。
不行的根本原因在于汉诺塔中的 printf 会带来全局的副作用。但 C/C++ 遵循 “顺序执行” 的原则,函数的执行有 “先后” (不像数学的函数,先后是无关的),按照不同顺序调用会导致程序输出不同的结果。实际上,C 标准中 return f(n - 1) + f(n - 2); 甚至不保证从左到右的调用顺序。(但现代编译器为了防止产生难以理解的执行,通常按照自然顺序调用、不做激进优化。)
C 解释执行器
虽然我们不大费周章去实现一个 SimpleC 的解释器 (烧一些 tokens 完全也可以做到),但我们可以在 gdb 中模拟这个效果:我们可以主动把程序改写成 SimpleC 的形式,在 gdb 中单步,就收集到了程序运行的状态和迁移,从而反过来 “看” 解释器是如何执行的。
汉诺塔
汉诺塔是递归和分治的经典问题,而同学们也曾经在理解这个程序的时候遇到困难。遇到困难是正常的:C/C++ 中的 “函数” 和数学的函数很不一样,例如我们可以把 Fibonacci 数列的递归写成
int x = f(n - 1);
int y = f(n - 2);
// 也可以 return y + x;
return x + y;
或是任意调换函数调用的次序,但汉诺塔不行。
不行的根本原因在于汉诺塔中的 printf 会带来全局的副作用。但 C/C++ 遵循 “顺序执行” 的原则,函数的执行有 “先后” (不像数学的函数,先后是无关的),按照不同顺序调用会导致程序输出不同的结果。实际上,C 标准中 return f(n - 1) + f(n - 2); 甚至不保证从左到右的调用顺序。(但现代编译器为了防止产生难以理解的执行,通常按照自然顺序调用、不做激进优化。)
什么是编译器
“编译器是一种将高级语言转换为低级语言的程序。” 这个定义不错;但到底什么是 “编译正确”?编译正确意味着对于任何输入,编译后程序的执行结果都和执行 C 语言形式语义的结果等价 (包括输出和终止)。这个定义其实给了编译器很多优化的空间——例如,所有最终 “用不上” 的计算都可以抹去。现在的编译器为了确保编译正确性,能做的优化相对有限,一个著名的论断是 “编译器不能把冒泡排序优化成快速排序”——虽然在今天也许不再是这样了。
最小可执行文件
为了理解操作系统上的程序,我们的目标是构造一个能直接被操作系统加载且打印 Hello World 的指令序列。如果你能想到这一点,剩下的一切都可以让 AI 帮助你。
探索 CPU Reset
我们都知道完整的计算机系统是从 CPU Reset 开始的。这里提供了三个架构的 “最小代码” 演示,展示 CPU Reset 后立即执行 “结束” 代码的短小程序,并打印出执行的指令序列和寄存器变化。运行程序,我们可以明确地看到 CPU Reset 后的寄存器状态,以及执行指令的结果:计算机世界没有任何魔法。
CIH 病毒
CIH (也称为 Chernobyl 病毒) 是台湾大同大学学生陈盈豪于 1998 年创建的,能够影响早期的 Windows 9x (95、98、Me) 操作系统。在 AI 的帮助下,我们把病毒代码翻译成了 “好读” 的 C 语言,可以清晰地看到病毒感染、潜伏和破坏的过程。
调试 SeaBIOS 固件
课程和互联网上的文档都声称是 Firmware 代码将具有 55 aa Magic Number 磁盘的前 512 字节载入内存。经过一些尝试 (例如修改 Magic Number),我们确认了这一行为;更进一步地,我们能否调试固件的代码,看看到底是什么指令实现了磁盘到内存的搬运?这就用到了《计算机系统基础》实验中的 Watch Point。在这里,我们还用到了 init.gdb,它可以帮我们省去每次运行时的重复输入命令,也可以设置 hook (钩子),每当程序暂停时显示一些我们关心的信息——我们定制和扩展了 gdb,使它在调试专属于我们的任务时更加强大。
OpenSBI
一个开源的 RISC-V 引导固件,用于管理 RISC-V 平台的启动过程。它实现了 SBI(Supervisor Binary Interface)规范,为操作系统提供了硬件抽象层,简化了系统启动和硬件管理。OpenSBI 支持多种 RISC-V 处理器和平台,广泛用于嵌入式系统和开发板。https://github.com/riscv-software-src/opensbi
1.2. Virtualization
Crazy OS
我们希望 “模拟” 一个操作系统:crazy-os.c 能加载 argv 指定的 binary (p1, p2, …),基于 mini-rv32ima.h 模拟单步执行 (RISC-V 指令),并能够处理 syscall。
展示进程信息
操作系统为每个进程都维护了二进制文件之外 “操作系统” 意义上的状态。实现一个 C 语言工具 (假设 Linux 系统),不调用外部工具,尽可能地获取并展示出进程自身不直接可见的操作系统状态。
创建一棵进程子树
创建一棵 5 层的进程树,并随机退出其中的一些进程——我们可以观察进程退出前后父子进程的关系。
fork-based DFS
如果我们使用深度优先搜索,总是需要维护当前的 “搜索状态”。通常这是通过将状态作为参数传递实现的 (当然,也可以用维护全局状态的方式实现)。借助 fork(),我们可以在每个搜索分支创建一个当前状态的快照,实现并行搜索。
理解 fork()
fork() 会完整复制状态机;新创建的状态机返回值为 0,执行 fork() 的进程会返回子进程的进程号。同时,操作系统中的进程是并行执行的。程序的精确行为并不显然——model checker 可以帮助我们理解它。在这个例子中,我们还发现执行 ./a.out 打印的行数和 ./a.out | wc -l 得到的行数不同。根据 “机器永远是对的” 的原则,我们可以通过提出假设 (libc 缓冲区影响) 求证、对比 strace 系统调用序列等方式,最终理解背后的原因。标准输入输出的缓冲控制可以通过 setbuf(3) 和 stdbuf(1) 实现。
理解 execve
execve 有三个参数:path, argv, envp,分别是可执行文件的路径、传递给 main 函数的参数和环境变量。execve 是一个 “底层” 的系统调用,而 POISX 额外提供了 execl 等库函数便于我们使用。请搜索互联网或询问人工智能理解它们的区别。
理解 exit
除了 libc 为我们提供的 exit 函数之外,Linux 提供了两个系统调用:exit 和 exit_group,它们可以在 syscalls(2) 的手册中看到。同时,你也可以在这份手册中看到 Linux 肩负的 “历史包袱”。strace 可以查看应用程序是如何 “退出” 的。
重新理解指针
编写一个 C 程序,用指针指向不同的位置:代码、数据、栈,打印地址,并从中读出一些数据。并且验证指向 main 指针读取到的数据确实是 main 的二进制代码。
探索进程地址空间
我在课堂上学习了 Linux 进程的地址空间。请你帮我做一个命令行工具,从命令行接收一个 pid,解析它的地址空间,输出每个部分是什么,如果是可执行的区域,把第一个 KB 的内容反汇编 (要兼容 x86-64 和 arm64)。
mmap 系统调用
Linux 系统使用 anonymous 的 mmap 来实现大段连续内存的分配——甚至在系统调用返回的瞬间,进程可以没有得到任何实际的内存,而是只要在首次访问时 (触发缺页异常) 分配即可。AddressSanitizer 就用 mmap 分配了 shadow memory,我们可以使用 strace 观察到这一点。
金山游侠
通过操作系统赋予我们实现调试器的机制,我们可以窥探甚至修改任何进程的代码和数据。这个能力使我们可以绕过游戏为我们设置的 “人为障碍”,取得更多的金钱、经验,或是锁定生命值等。
文件描述符
文件描述符是一个用于访问文件或其他输入/输出资源的 “指针”。在 Unix 和类 Unix 操作系统中,文件描述符是一个非负整数,用于表示一个打开的文件、管道、网络连接或其他类似的资源。当一个程序打开一个文件或创建一个数据流时,操作系统会返回一个文件描述符,程序可以通过这个描述符来读取、写入或操作对应的文件或资源。
UNIX 管道
UNIX 管道 (pipe) 是一种典型的进程间通信机制,允许数据在不同的进程之间单向流动。管道可以被视为一种特殊的文件,其中一个进程将数据写入管道的一端,而另一个进程从另一端读取数据。我们完全可以借助 AI 生成的辅助可视化工具来理解这一过程。
TestKit 测试框架
Writing test cases fearlessly! 这是同学们的第一个测试框架:支持单元测试和系统测试,自动注册测试用例并在程序退出后运行。最重要的特点是它使用简单:你只需要包含 testkit.h,并且链接 testkit.c 即可。
理解终端
我们可以让 AI 实现各类终端控制的程序——包括一个在终端里的终端模拟器,去理解操作系统提供了怎样的对象和 API 来帮助我们操作终端设备。
信号处理
我们可以通过 signal (sigaction) 注册信号处理程序——这也解释了为什么有些程序不能用 Ctrl-C 退出。即便是终止信号,我们也可以执行清理代码退出。
Shebang
在 UNIX 的早期,为了能更方便地将脚本作为可执行文件,实现了 #! 开头的 “可执行文件”,并沿用至今。Shebang 会调用第一行中执行的命令和参数,并把这个脚本文件作为命令行参数传入。
调试 “小程序”
再次回到学习 C 语言时 “最简单” 的例子;但当我们有了操作系统的知识以后,我们就可以深入调试其中的每一个细节。从汇编指令到系统调用到,我们可以看到程序和处理器、操作系统的所有交互。
Funny Little Executable
我们 “自行设计” 了能实现 (静态) 链接和加载的二进制文件格式,以及相应的编译器、链接器 (复用 gcc/ld) 和加载器。FLE 文件直接将一段可读、可写、可执行的位置无关代码连通数据映射到内存并跳转执行。
Shebang
在 UNIX 的早期,为了能更方便地将脚本作为可执行文件,实现了 #! 开头的 “可执行文件”,并沿用至今。Shebang 会调用第一行中执行的命令和参数,并把这个脚本文件作为命令行参数传入。
动态链接库是进程间共享的吗?
试着创建一个 10M nop 组成的 bloat(),编译在 libbloat.so,然后创建 1000 个进程动态链接它。如果 libbloat.so 的每个进程都有一份副本,那么系统的内存占用应该会达到 10GB。
变速齿轮
实现 “变速齿轮”:通过 LD_PRELOAD 机制覆盖和时间相关的系统调用 (gettimeofday, usleep, alarm 等),通过在启动时记录时间并维护 10 倍速度的虚拟时间实现变速。
Minix
Minix 是 UNIX 之后的经典教学操作系统,Andrew Tanenbaum 也因此成就了一代计算机系统研究者。代码来自 Minix 1 and 2, Quick and Dirty editions。
最小 Linux
我们完全可以构建一个 “只有一个文件” 的 Linux 系统——Linux 系统会首先加载一个 “init RAM Disk” 或 “init RAM FS”,在作系统最小初始化完成后,将控制权移交给 “第一个进程”。借助互联网或人工智能,你能够找到正确的文档,例如 The kernel’s command-line parameters 描述了所有能传递给 Linux Kernel 的命令行选项。
Linux
我们可以在 initramfs 中放置任意的数据——包括应用程序、内核模块 (驱动)、数据、脚本……操作系统世界已经开始运转;但直到执行 pivot_root,才真正开始 今天 Linux 应用世界 (systemd) 的启动。
1.3. Concurrency
迷你线程库
在这个 “最简” 的线程库中,我们封装了 POSIX 线程库,提供了线程管理的 API:spawn(fn) 创建一个新线程,执行函数 fn;join() 等待当前运行的线程结束。使用这两个 API,我们就可以利用系统中的多处理器资源了:线程可以被同时调度到不同的处理器上并行执行。
通过线程库理解线程行为
我们可以不必 “直接接受” 老师或书本上的知识,而是亲手验证它们,例如线程的确是共享内存的,再比如验证每个线程都有独立的栈——我们可以把 “访问过” 的栈空间标记出来,从而得到每个线程栈的大概范围。
山寨支付宝
由于线程调度可能随时随地发生,人类并不擅长理解它们的行为。与其他的编程语言特性联系在一起,就可能产生糟糕的后果——尤其是在有 undefined behavior 的编程语言 (例如 C/C++) 中,可能导致诸多安全漏洞。
使用 mutex API 实现互斥
我们的线程库提供了 mutex_lock, mutex_unlock 的 API 实现互斥。
宽松内存模型
我们简化理解多处理器的状态机模型时假设了每次选择一个处理器执行一条指令。然而,由于动态指令调度和缓存的共同作用,实际程序的运行结果更可能超出我们的预期。
尝试关闭中断
在单处理器系统中,关闭中断即可实现 “stop the world” 的效果,消除并发/并行的可能性。我们尝试在进程中也调用关闭中断的指令。
使用 mutex API 实现互斥
我们的线程库提供了 mutex_lock, mutex_unlock 的 API 实现互斥。
操作系统模型和检查器
我们可以把 “状态机的管理者” 这个思想在 Python 世界中构造出来:我们用 Python 的函数来声明状态机,并且实现状态空间的遍历。所有的实现都是 “最简” 的——但它真的能用来澄清 Three Easy Pieces 里的概念:Concurrency, Virtualization, 和 Persistence。
Peterson 算法
在宽松内存模型上,Peterson 算法既低效又很难实现。直接用 load/store 实现互斥并不是正确的努力方向。
使用硬件原子指令实现互斥
我们的线程库也提供了 spin_lock, spin_unlock 的 API 实现互斥,直接用 inline assembly 调用指令集实现——在实际上,GCC 提供了 __atomic_compare_exchange_n 的 built-in 帮助我们实现跨体系结构的可移植性:例如,armv8.1 加入了新的原子指令,使用正确的编译选项可以获得最佳的性能。
使用不同方式求和
我们对比使用自旋锁 (手工实现)、互斥锁和原子指令在求和上的性能,做一个基础的控制变量的对比实验:确定总的 sum++ 次数不变,分布在 T = 1, 2, 4, 8, 16 个线程,分别为三种实现实验重复 5 次,统计一次 sum++ 的平均时间。保存原始数据的列表 (csv),并且在 Jupyter Notebook 里生成带 error bar 的 plot。
实现乐团同步
乐团指挥希望每个成员在听到指挥的信号后,才开始演奏一拍——也就是建立一个 “happens-before” 的关系。在代码中,我们可以通过 happens-after 的一方 “等待” 同步条件达成的方式来实现同步。这个想法形成了条件变量。我们可以对比使用 spin 和条件变量版本的乐团指挥。
生产者-消费者问题
在解决同步问题时,关键在于理解全局同步点上的同步条件是什么。然后各个线程在条件不满足时等待,直到条件满足方可继续。这个思路自然地引出了 “条件变量” 这一同步机制。
奇怪的同步问题
我们可以构造出 “奇怪” 的同步条件,例如有三种线程,分别死循环打印 <、>、_。如何同步这些线程,使得屏幕上看到的总是 <><_ 和 ><>_ 的组合?而只要我们能列出同步条件,就可以直接使用条件变量解决。
使用互斥锁实现计算图
为每一条边分配一把互斥锁——对于 u->v 的一条边,通过在 main 函数 acquire(lock of u -> v),u release -> v acquire 来实现 happens-before。注意虽然这个程序可以正常运行,但这是 pthread mutex 不允许的 undefined behavior。
使用互斥锁实现计算图
为每一条边分配一把互斥锁——对于 u->v 的一条边,通过在 main 函数 acquire(lock of u -> v),u release -> v acquire 来实现 happens-before。注意虽然这个程序可以正常运行,但这是 pthread mutex 不允许的 undefined behavior。
使用信号量实现线程 join
我们既可以用一个信号量实现一次临时的 happens-before,也可以用一个计数型信号量等待数量正确的线程结束。
使用信号量实现计算图
使用信号量 “计数” 的特征,我们可以为每个节点分配信号量,当获得和入边数量相同的钥匙时,就可以进入该节点并开始计算。
使用信号量实现生产者-消费者问题
信号量给了生产者-消费者问题一个非常精巧的实验,生产者把球从 empty 口袋取走,push 之后把球放入 filled 口袋;消费者则恰好相反。整个系统满足 empty + filled + 正在打印的线程 = 缓冲区大小的全局约束。
哲学家吃饭问题
通过一个额外的信号量,我们限制上桌吃饭的人数不超过 4 人。上桌的 4 人之中至少有一人可以获得左右手的叉子,然后释放后退出临界区。这个协议的正确性并不是显然的:我们必须非常小心地对待任何并发问题。
死锁演示
包含两种经典的死锁场景:AA 死锁:同一个线程对同一把互斥锁加锁两次。由于 mutex 不可重入,线程在第二次 mutex_lock 时永远阻塞。ABBA 死锁:哲学家就餐问题。每个哲学家先拿左手边的叉子、再拿右手边的叉子——当所有人都拿到左手边叉子时,形成循环等待,所有线程永久阻塞。
lockdep
通过 LD_PRELOAD 拦截 pthread_mutex_lock / pthread_mutex_unlock,在运行时构建锁的依赖图(邻接矩阵)来检测潜在的 ABBA 死锁:每次加锁时记录 “已持有锁 → 新获取锁” 的有向边,加边前检查是否形成环,发现环则报告潜在死锁。
ThreadSanitizer
通过寻找是否存在没有 happens-before 关系的不同线程、同一变量、至少一个是写的内存访问 (数据竞争)。这也称为 happens-before race。同时,TSAN 也不是万能的:触发 happens-before race 依然可能需要特定的线程调度。
Therac-25 模拟器
完全的 vibe coding,没有任何古法编程——在 Content-as-Code 的时代,编程前所未有地简单,我们也可以随时随地生成任何辅助的工具——从教具到 3D 打印的工具。
绘制 Mandelbrot Set
Mandelbrot set 描绘了函数 f(z) = z^2 + c 的轨迹是否有界。对于复平面上每一个点,求值都是完全独立的,因此对计算图的静态划分也是显然的。我们混用了 OpenMP 和我们的线程库。我们的线程库仅限于隔一段时间将当前渲染的结果显示在屏幕上,并在所有线程结束后输出渲染图。
Thread-local Storage
C/C++ 支持声明 “线程局部” 的变量,在编译器的配合下,会生成 “每个线程独立” 的拷贝,从而避免维护全局 map<tid,thread_local_storage> 映射的开销。
线程的代价
我们可以通过创建线程、统计系统的资源变化,来估算创建线程所占用的资源。
轻量级线程的实现
我们可以不在操作系统中分配额外的资源,而是仅用进程自身的地址空间和指令集实现多个执行流的切换。既可以在编程语言的帮助下实现无栈的轻量级线程,也可以实现栈切换。
Mandelbrot-Go
多个 goroutine 按行分块并行计算 Mandelbrot 集,通过 channel (done) 汇报完成,monitor 用 select 同时监听完成信号和定时器实现实时预览,最终由 finish channel 通知主线程退出。
Web 和事件编程
这里展示了如何从 shopper.html 充满了 setInterval、DOM 操作和事件驱动的动画,到 modernize.js 将其瞬间改造为今天的页面风格。
指令级并行 (ILP)
在树莓派 2 (Cortex-A7, 顺序双发射) 上用内联汇编构造不同数据依赖关系的指令序列(依赖链、独立整数、VFP 浮点、NEON SIMD、整数+浮点混合、独立乘法),通过 perf stat 测量每种模式下的 IPC (Instructions Per Cycle),直观感受处理器如何利用指令级并行提升性能。
OpenGL Shader
我们可以用 “套娃” 的方式在程序中嵌入一个 GLSL 的 shader program。这会经历一个完整的编译流程,并最终作用到对应的像素上。
CUDA 实现的 Mandelbrot Set
和 “原版” C 代码对比,实际计算的 mandelbrot 函数完全没有任何修改,只是增加了 “kernel” 的修饰。此外,worker 线程被 mandelbrot_kernel 函数取代,这个函数在 GPU 上运行,通过 blockIdx, blockDim 和 threadIdx 计算出线程对应的像素坐标。没错,CUDA 是另一种 “启动百千万个轻量级线程” 的机制。
一个 LLM Request
在地球上的任何一个地方,只要能接入互联网,通过 requests 库请求 DeepSeek API endpoint,就能够直接启动和 AI 的聊天。很难想象短短数年时间,全人类都在使用的新基础设施就已经建设完毕了。
1.4. Persistence
GPIO LED
计算机上的任何 I/O 设备都是可以通过程序控制的——只是通常并不推荐这么做:我们有丰富的应用程序抽象可以帮助我们更好地完成设备的交互。
PostScript
PostScript是一种页面描述语言 (PDL),由 Adobe Systems 在 1980 年代初开发。它是一种编程语言,专门用于描述图形和文本的布局和外观,主要用于打印和显示系统。PostScript 文件包含了详细的指令,告诉打印机或显示设备如何生成页面上的每一个元素,包括字体、图形、颜色和图像。
一个设备驱动程序
理解了设备驱动程序的职责是把系统调用 “翻译” 成与设备能听懂的数据,我们也可以实现 struct file_operations 中相应的操作,从而模拟一个设备。
KVM Device
KVM 设备提供了硬件虚拟化的机制,允许我们在用户空间通过 /dev/kvm 在虚拟化的环境中运行一段代码直到 VM Exit。
WebCam
USB Video Class (UVC) 是 USB 设备类规范,定义了视频流设备无需额外驱动即可通过标准 USB 接口传输未压缩或压缩视频数据的通信协议。Linux通过 Video for Linux 2 (V4L2) 子系统将其抽象为 /dev/videoX 设备节点,并提供标准 ioctl 接口 (如查询格式、设置帧率、申请缓冲区) 和内存映射 (mmap) 或用户指针方式获取视频帧。
打开 Linux Block I/O
让我们借助 Coding Agent,“在没有直接经验的领域(如语言、技术、框架等)进行一些编程工作” 吧!虽然我作为《操作系统》的教师,知道 Linux 内核内部的机制,但我决定在对话时假装自己对系统内的这些机制一无所知。模型:deepseek-v4-pro (high),成本:¥ 0.72。
Symlink Game
我们可以使用符号链接创建 “近乎任意” 的目录结构,包括任意的图结构 (状态机),操作系统也能正确解析。操作系统的机制 (系统调用、文件系统……) 给了我们无限的创作空间。
OverlayFS
一种联合文件系统,允许将多个目录 “层叠” 在一起,形成单一的虚拟目录。OverlayFS 是容器 (如 docker) 的重要底层机制。它也可以用于实现文件系统的快照、原子的系统更新等。
Logic Volume Manager
Logical Volume Manager (LVM) 是 Linux 中用于虚拟化存储设备的工具。它允许将物理卷 (Physical Volume, PV) 组成卷组 (Volume Group, VG),然后从卷组中创建逻辑卷 (Logical Volume, LV)。
readfat
通过摘抄手册,可以得到 fat32.h 并明确每个字段的含义,mmap 把磁盘镜像映射到内存就可以实现解析了。现在这个工作,哪怕是全新的系统,也完全可以交给大语言模型完成。
Debug File Systems
debugfs 工具使我们能在用户态调试文件系统——这也给了我们 “可视化” 一个目录的机会,我们可以递归地 dump 出一个目录的 raw data structure,看到文件系统的 “内部”,例如符号链接是如何存储的,并且用合适的工具渲染成直接可视化的 diagram。
Crash Consistency Checker
一个 user-space 的 strace-based crash consistency checker。追踪一次程序所有对数据文件的写入,包括 fsync 系列的系统调用,生成一系列的 trace,并使用 LLM 判定是否存在数据不一致等。
Memory-mapped 数据结构
如果我们总是把数据结构映射到固定的位置 (并且为数据结构的分配使用专用的分配器,总是从固定位置分配),就可以直接把数据结构映射到磁盘上,甚至也可以实现 write-ahead log。
2. 回望过去
上操作系统课的意义
在课堂上时,你可以思考一些已经很清楚的基本东西。这些知识是很有趣、令人愉快的,重温一遍又何妨?另一方面,有没有更好的介绍方式?有什么相关的新问题?你能不能赋予这些旧知识新生命?……但如果你真的有什么新想法,能从新角度看事物,你会觉得很愉快。
学生问的问题,有时也能提供新的研究方向。他们经常提出一些我曾经思考过、但暂时放弃、却都是些意义很深远的问题,重新想想这些问题,看看能否有所突破,也很有意思。
学生未必理解我想回答的方向,或者是我想思考的层次;但他们问我这个问题,却往往提醒了我相关的问题。单单靠自己,是不容易获得这种启示的。 —— Richard P. Feynman
Teaching is a powerful tool to learn.
- 期待一下我们的下一份工作
- 可以在这学期的课程里找到它的影子

我们身处的时代
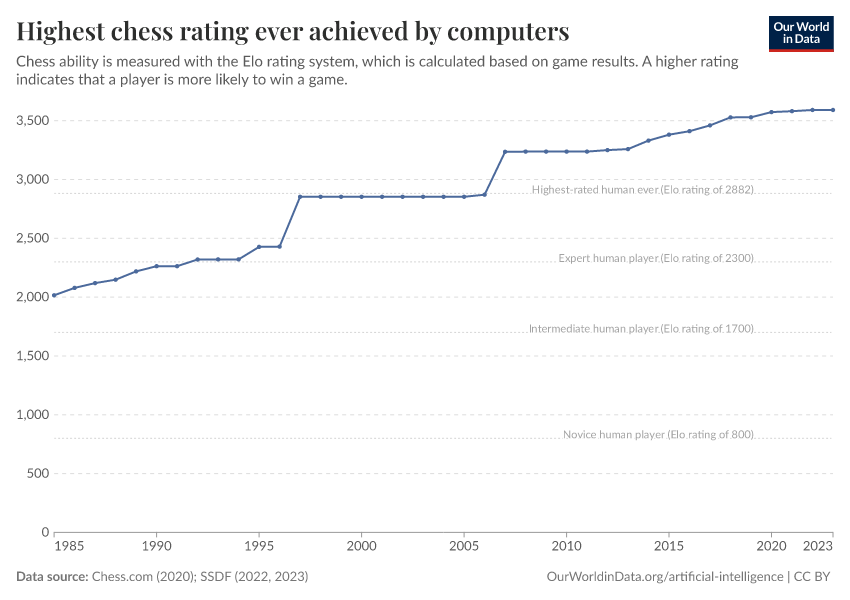
DeepBlue (1997) 不是偶然的
我们身处的时代 (cont’d)
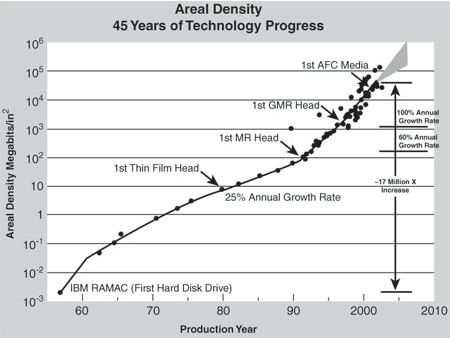
Google (1998) 不是偶然的
我们身处的时代 (cont’d)
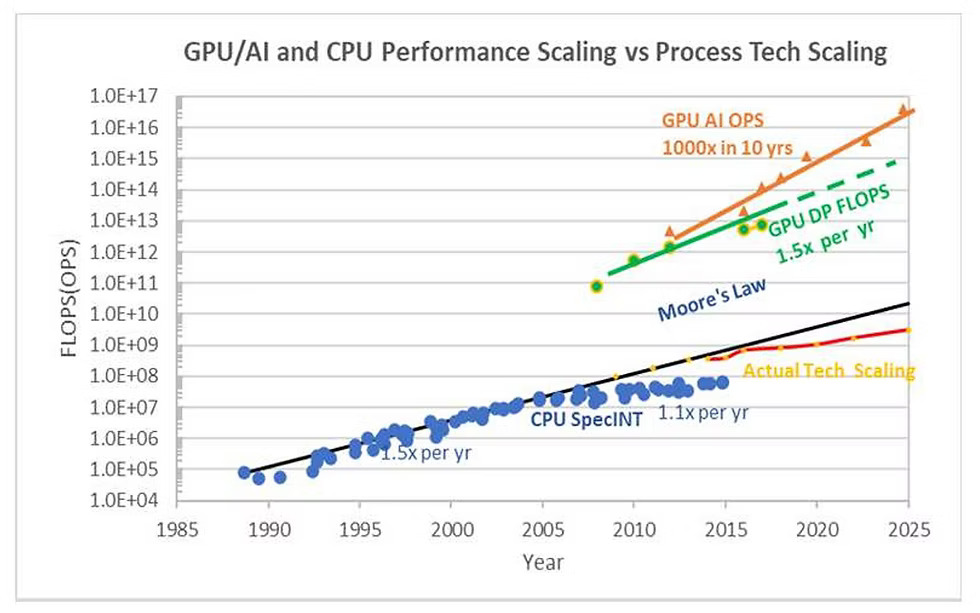
Intel (1968) 和 Nvidia (1993) 更不是偶然的
我们身处的时代 (cont’d)
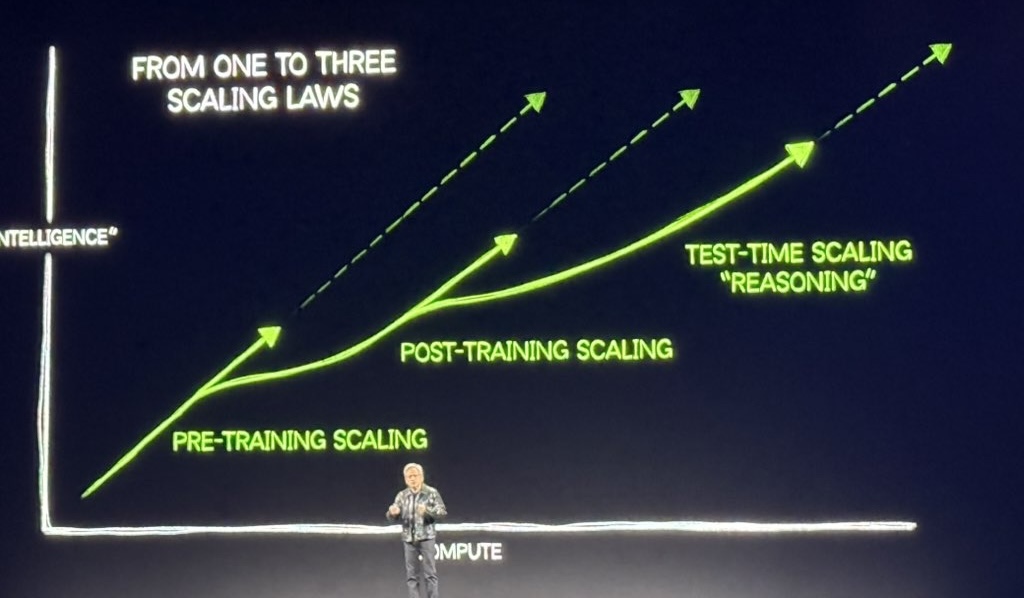
OpenAI (2015) 当然也不是偶然的
3. 走向未来
AGI 的迫近
只要有足够好的 training-time scaling, test-time scaling 的上限就是近乎无限的。