为 Bare-Metal 编程:编译、链接与加载
1. 从一个例子说起
阅读本文档需要能够阅读汇编语言——不用怕,它们代表了状态机的迁移函数。在遇到不熟悉的地方,请 STFW/RTFM。
Bare-metal 运行的程序和操作系统上的程序不一样——当我们面对 bare-metal 的时候,几乎每一行代码都是自己编写的,包括库函数,甚至连帮我们加载 main 函数的代码都需要自己写。
因此,怎样让 C 程序运行起来,是 “写操作系统” 新手最大的困惑之一,如果思考一下:
- 为了使程序能运行,当然需要经过编译链接的过程。就假设最简单的情况:生成静态链接的 ELF 格式的二进制文件好了。
- 二进制文件假设代码、数据存在于地址空间的指定位置。那么是谁来完成这件事?
main在二进制文件中的地址是不固定的。是谁调用的main()?- 我们需要自己动手实现各种库函数,那
printf(输出到屏幕),malloc(动态分配内存)又是如何实现的?
为了理解 C 程序是如何运行在裸机 (bare-metal) 上的,我们首先理解 C 程序是如何从源代码 (文本文件) 最终在操作系统上运行起来的。为此,我们讲解一个小例子 (say.c 和 main.c 组成的小项目) 在操作系统上以及 AbstractMachine 上的编译、链接和加载运行的过程。
// say.c
void putch(char ch);
int putchar(int ch);
void say(const char *s) {
for (; *s; s++) {
#ifdef __ARCH__
putch(*s); // AbstractMachine,没有 libc,调用 TRM API 打印字符
#else
putchar(*s); // 操作系统,调用 libc 打印字符
#endif
}
}
// main.c
void say(const char *s);
int main() {
say("hello\n");
}
以下完整的流程是操作系统上 (hosted) 和 bare-metal 上共同的:
main.c -> 编译 (gcc -c) -> a.o -+
\
say.c -> 编译 (gcc -c) -> b.o -> 链接 (ld) -> a.out -> 加载 (loader)
2. 操作系统上的 C 程序
2.1. 编译
我们使用 gcc 把源代码编译成可重定位的二进制文件:
$ gcc -c -O2 -o main.o main.c
$ gcc -c -O2 -o say.o say.c
$ file say.o main.o
say.o: ELF 64-bit LSB relocatable, x86-64, version 1 (SYSV), not stripped
main.o: ELF 64-bit LSB relocatable, x86-64, version 1 (SYSV), not stripped
“relocatable” 的含义是虽然生成了指令序列,但暂时还不确定它们在二进制文件中的位置。我们可以查看生成的指令序列:
$ objdump -d main.o
0000000000000000 <main>:
0: 48 8d 3d 00 00 00 00 lea 0x0(%rip),%rdi # 7 <main+0x7>
7: 48 83 ec 08 sub $0x8,%rsp
b: e8 00 00 00 00 callq 10 <main+0x10>
10: 31 c0 xor %eax,%eax
12: 48 83 c4 08 add $0x8,%rsp
16: c3 retq
可以看到 relocatable 的代码从 0 开始编址;因为 main 并不知道 say 的代码在何处,所以虽然生成了 opcode 为 0xe8 的 call 指令 (对应 say("...") 的函数调用),但没有生成跳转的偏移量 (say.c 中向 putchar 的调用也生成同样的 call 指令):
b: e8 00 00 00 00 callq 10 <main+0x10>
类似的,say 的第一个参数 (通过 %rdi 寄存器传递) 是通过如下 lea 指令获取的,它的位置同样暂时没有确定:
0: 48 8d 3d 00 00 00 00 lea 0x0(%rip),%rdi # 7 <main+0x7>
2.2 链接
通常,我们使用 gcc 帮助我们完成链接:
$ gcc main.o say.o
$ ./a.out
hello
如果直接使用 ld 命令链接,则会报错:
$ ld main.o say.o
ld main.o say.o
ld: warning: cannot find entry symbol _start; defaulting to 00000000004000b0
say.o: In function `say':
say.c:(.text+0x15): undefined reference to `putchar'
首先,我们的程序没有入口 (_start),其次,我们链接的对象中没有 putchar 函数。我们可以给 gcc 传递额外的参数,查看 ld 的选项:
gcc -Wl,--verbose main.o say.o
你会发现链接的过程比想象中复杂得多。用以下简化了的命令可以得到可运行的 hello 程序:
$ ld -dynamic-linker /lib64/ld-linux-x86-64.so.2 \
/usr/lib/x86_64-linux-gnu/crt1.o \
/usr/lib/x86_64-linux-gnu/crti.o \
main.o say.o -lc \
/usr/lib/x86_64-linux-gnu/crtn.o
$ ./a.out
hello
为什么这么复杂?还有好多没见过的文件!这是因为我们的二进制文件要运行在操作系统上,就必须遵循操作系统的规则,调用操作系统提供的 API 完成加载。加载器也是代码的一部分,当然应该被链接进来。链接文件的具体解释:
ld-linux-x86-64.so负责动态链接库的加载,没有它就无法加载动态链接库 (libc)。crt*.o是 C Runtime 的缩写,即 C 程序运行所必须的一些环境,例如程序的入口函数_start(二进制文件并不是从main开始执行的!)、atexit注册回调函数的执行等。-lc表示链接 glibc。
链接后得到一个 ELF 格式的可执行文件:
$ file a.out
a.out: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/l, for GNU/Linux 3.2.0, not stripped
$ objdump -d a.out
...
0000000000400402 <main>:
400402: 55 push %rbp
400403: 48 89 e5 mov %rsp,%rbp
400406: 48 8d 3d c7 00 00 00 lea 0xc7(%rip),%rdi # 4004d4 <_IO_stdin_used+0x4>
40040d: b8 00 00 00 00 mov $0x0,%eax
400412: e8 07 00 00 00 callq 40041e <say>
400417: b8 00 00 00 00 mov $0x0,%eax
40041c: 5d pop %rbp
40041d: c3 retq
000000000040041e <say>:
40041e: 55 push %rbp
40041f: 48 89 e5 mov %rsp,%rbp
400422: 48 83 ec 10 sub $0x10,%rsp
400426: 48 89 7d f8 mov %rdi,-0x8(%rbp)
40042a: eb 16 jmp 400442 <say+0x24>
40042c: 48 8b 45 f8 mov -0x8(%rbp),%rax
400430: 0f b6 00 movzbl (%rax),%eax
400433: 0f be c0 movsbl %al,%eax
400436: 89 c7 mov %eax,%edi
400438: e8 83 ff ff ff callq 4003c0 <putchar@plt>
40043d: 48 83 45 f8 01 addq $0x1,-0x8(%rbp)
400442: 48 8b 45 f8 mov -0x8(%rbp),%rax
400446: 0f b6 00 movzbl (%rax),%eax
400449: 84 c0 test %al,%al
40044b: 75 df jne 40042c <say+0xe>
40044d: 90 nop
40044e: c9 leaveq
40044f: c3 retq
...
2.3. 加载
警告:大量的细节
程序加载的过程十分复杂,甚至有一些你目前可能暂时难以理解的地方 (例如 vvar, vdso, 变化的
a.out等)。我们会用一学期的课程回答这些问题。所以遇到不明白的地方,跳过即可。随着课程的进展,你对这个过程的理解会不断加深。
完成链接后,在操作系统的终端程序中使用 ./a.out 运行我们的程序,流程大致如下 (学完《操作系统》课后,你将会对这个流程有更深入的认识):
- Shell 接收到命令后,在操作系统中使用
fork()创建一个新的进程。 - 在子进程中使用
execve()加载a.out。操作系统内核中的加载器识别出a.out是一个动态链接文件,做出必要的内存映射,从ld-linux-x86-64.so的代码开始执行,把动态链接库映射到进程的地址空间中,然后跳转到a.out的_start执行,初始化 C 语言运行环境,最终开始执行main。 - 程序运行过程中,如需进行输入/输出等操作 (如 libc 中的
putchar),则会使用特殊的指令 (例如 x86 系统上的int或syscall) 发出系统调用请求操作系统执行。典型的例子是printf会调用write系统调用,向编号为1的文件描述符写入数据。
怎么在实际的系统上观察上述的行为?我们有调试器!gdb 为我们提供了 starti 指令,可以在程序执行第一条指令时就停下:
$ gdb a.out
GNU gdb (Ubuntu 8.1-0ubuntu3.2) 8.1.0.20180409-git
...
(gdb) starti # 启动程序,并在第一条指令上暂停
Starting program: /tmp/a/a.out
Program stopped.
0x00007ffff7dd6090 in _start () from /lib64/ld-linux-x86-64.so.2
(gdb) bt f # backtrace full,打印堆栈信息
#0 0x00007ffff7dd6090 in _start () from /lib64/ld-linux-x86-64.so.2
library_path = 0x0
version_info = 0
any_debug = 0
_dl_rtld_libname = {name = 0x0, next = 0x0, dont_free = 0}
relocate_time = 0
_dl_rtld_libname2 = {name = 0x0, next = 0x0, dont_free = 0}
start_time = 0
tls_init_tp_called = false
load_time = 0
audit_list = 0x0
preloadlist = 0x0
__GI__dl_argv = 0x0
_dl_argc = 0
audit_list_string = 0x0
_rtld_global = {_dl_ns = {{_ns_loaded = 0x0, _ns_nloaded = 0,
...
#1 0x0000000000000001 in ?? ()
No symbol table info available.
...
操作系统的加载器完成了 ld-linux-x86-64.so.2 的加载,并给它传递了相应的参数。我们可以查看此时的进程信息 (这些内存都是操作系统加载的):
(gdb) info inferiors # 打印进程/线程信息
Num Description Executable
* 1 process 18137 /tmp/hello/a.out
(gdb) !cat /proc/18137/maps # 打印进程的内存信息
00400000-00401000 r-xp 00000000 08:02 3538982 /tmp/hello/a.out
00600000-00602000 rw-p 00000000 08:02 3538982 /tmp/hello/a.out
7ffff7dd5000-7ffff7dfc000 r-xp 00000000 08:02 4985556 /lib/x86_64-linux-gnu/ld-2.27.so
7ffff7ff7000-7ffff7ffa000 r--p 00000000 00:00 0 [vvar]
7ffff7ffa000-7ffff7ffc000 r-xp 00000000 00:00 0 [vdso]
7ffff7ffc000-7ffff7ffe000 rw-p 00027000 08:02 4985556 /lib/x86_64-linux-gnu/ld-2.27.so
7ffff7ffe000-7ffff7fff000 rw-p 00000000 00:00 0
7ffffffde000-7ffffffff000 rw-p 00000000 00:00 0 [stack]
ffffffffff600000-ffffffffff601000 r-xp 00000000 00:00 0 [vsyscall]
如果我们在 _start 设置断点,会发现此时已经加载完成:
(gdb) b _start # breakpoint 设置断点
Breakpoint 1 at 0x4003d0
(gdb) c # continue 继续执行
Continuing.
Breakpoint 1, 0x00000000004003d0 in _start ()
(gdb) !cat /proc/18137/maps
00400000-00401000 r-xp 00000000 08:02 3538982 /tmp/hello/a.out
00600000-00601000 r--p 00000000 08:02 3538982 /tmp/hello/a.out
00601000-00602000 rw-p 00001000 08:02 3538982 /tmp/hello/a.out
7ffff79e4000-7ffff7bcb000 r-xp 00000000 08:02 4985568 /lib/x86_64-linux-gnu/libc-2.27.so
7ffff7bcb000-7ffff7dcb000 ---p 001e7000 08:02 4985568 /lib/x86_64-linux-gnu/libc-2.27.so
7ffff7dcb000-7ffff7dcf000 r--p 001e7000 08:02 4985568 /lib/x86_64-linux-gnu/libc-2.27.so
7ffff7dcf000-7ffff7dd1000 rw-p 001eb000 08:02 4985568 /lib/x86_64-linux-gnu/libc-2.27.so
7ffff7dd1000-7ffff7dd5000 rw-p 00000000 00:00 0
7ffff7dd5000-7ffff7dfc000 r-xp 00000000 08:02 4985556 /lib/x86_64-linux-gnu/ld-2.27.so
7ffff7fde000-7ffff7fe0000 rw-p 00000000 00:00 0
7ffff7ff7000-7ffff7ffa000 r--p 00000000 00:00 0 [vvar]
7ffff7ffa000-7ffff7ffc000 r-xp 00000000 00:00 0 [vdso]
7ffff7ffc000-7ffff7ffd000 r--p 00027000 08:02 4985556 /lib/x86_64-linux-gnu/ld-2.27.so
7ffff7ffd000-7ffff7ffe000 rw-p 00028000 08:02 4985556 /lib/x86_64-linux-gnu/ld-2.27.so
7ffff7ffe000-7ffff7fff000 rw-p 00000000 00:00 0
7ffffffde000-7ffffffff000 rw-p 00000000 00:00 0 [stack]
ffffffffff600000-ffffffffff601000 r-xp 00000000 00:00 0 [vsyscall]
地址空间中已有 a.out, libc, 堆区、栈区等我们熟悉的东西,libc 的 _start 完成初始化后会调用 main()。这真是一段漫长的旅途!
3. Bare-Metal 上的 C 程序
对于 AbstractMachine 上的程序,我们需要一个 Makefile,就能把 hello 程序编译到 bare-metal 执行:
NAME := hello
SRCS := main.c say.c
include $(AM_HOME)/Makefile.app
在终端中执行 make -nB ARCH=x86_64-qemu 可以查看完整的编译、链接到 x86-64 的过程 (不实际进行编译)。
3.1. 编译
编译器的功能是把 .c 文件翻译成可重定位的二进制目标文件 (.o)。这一步对于有无操作系统来说差别并不大,最主要的区别是在 bare-metal 是 “freestanding” 的运行环境,没有办法调用依赖于操作系统的库函数——你依然可以声明它们 (例如 printf, malloc 等),但最终它们的代码无法链接。
编译器 (gcc) 提供了选项帮我们生成不依赖操作系统的目标文件,例如对 -ffreestanding (-fno-hosted) 选项的文档:
Assert that compilation targets a freestanding environment. This implies
-fno-builtin. A freestanding environment is one in which the standard library may not exist, and program startup may not necessarily be at "main". The most obvious example is an OS kernel. This is equivalent to-fno-hosted.
除了编译器做出一些代码生成的限制之外,bare-metal 程序的编译和操作系统上程序没有任何区别。事实上,对于我们的示例程序来说,main 和 say 编译出的汇编代码是完全一致的,除了 relocation table 中的重定位信息不同 (bare-metal 上会调用 putch 而不是 putchar)。
3.2. 链接
可能出乎意料,因为没有操作系统,bare-metal 程序的链接比操作系统上的情况还简单一些!我们使用的链接命令是:
$ ld -melf_x86_64 -N -Ttext-segment=0x00100000 -o build/hello-x86_64-qemu.o \
main.o say.o am-x86_64-qemu.a klib-x86_64-qemu.a
只链接了 main.o, say.o 和必要的库函数 (AbstractMachine 和 klib;在这个例子中,我们甚至可以不链接 klib 也能正常运行)。使用的链接选项:
-melf_x86_64:指定链接为 x86_64 ELF 格式;-N:标记.text和.data都可写,这样它们可以一起加载 (而不需要对齐到页面边界),减少可执行文件的大小;-Ttext-segment=0x00100000:指定二进制文件应加载到地址0x00100000。
使用 readelf 命令查看 hello-x86_64-qemu.o 文件的信息:
$ readelf -a build/hello-x86_64-qemu.o
ELF Header:
Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00
Class: ELF64
Data: 2's complement, little endian
Version: 1 (current)
OS/ABI: UNIX - System V
ABI Version: 0
Type: EXEC (Executable file)
Machine: Advanced Micro Devices X86-64
Version: 0x1
Entry point address: 0x100100
Start of program headers: 64 (bytes into file)
Start of section headers: 65584 (bytes into file)
...
其中的 program headers 描述了需要加载的部分:加载这个文件的加载器需要把文件中从 0xb0 (Offset) 开始的 0x29ac 字节 (FileSiz) 加载到内存的 0x1000b0 虚拟/物理地址 (VirtAddr/PhysAddr),内存中的大小 0x23f98 字节 (MemSiz,超过 FileSiz 的内存清零),标志为 RWE (可读、可写、可执行)。
Program Headers:
Type Offset VirtAddr PhysAddr
FileSiz MemSiz Flags Align
LOAD 0x00000000000000b0 0x00000000001000b0 0x00000000001000b0
0x00000000000029ac 0x0000000000023f98 RWE 0x20
GNU_STACK 0x0000000000000000 0x0000000000000000 0x0000000000000000
0x0000000000000000 0x0000000000000000 RWE 0x10
实际上,这个程序可以直接在操作系统上被运行!如果你试着用 gdb 调试它,会发现程序从 _start (0x100100) 开始执行,但在执行了若干条指令后,在 movabs %eax,0xb900001000 时发生了 Segmentation Fault。
_start里没有movabs?x86-64 AbstractMachine 上程序的入口在
start64.S文件中:.code32 .globl _start _start: movl $(PDPT_ADDR | PTE_P | PTE_W), %eax cmpl (PML4_ADDR), %eax je .long_mode_init movl $(PDPT_ADDR | PTE_P | PTE_W), %eax movl %eax, (PML4_ADDR) ...这是一段 32-bit 代码——AbstractMachine 的加载器并没有进入 64-bit 模式;而
hello-x86_64-qemu.o直接在操作系统上执行时,将代码解析为 64-bit 汇编,因此错误解析了 32-bit 指令,访问非法内存产生 Segmentation Fault。
只不过因为运行环境不同,执行到系统指令时,属于非法操作 crash 了。我们需要在 bare-metal 上加载它。所以我们会创建 hello-x86_64-qemu 的镜像文件:
( cat abstract-machine/am/src/x86/qemu/boot/mbr \
head -c 1024 /dev/zero \
cat build/hello-x86_64-qemu.o ) \
> /tmp/hello/build/hello-x86_64-qemu
镜像文件是由 512 字节的 “MBR”、1024 字节的空白 (用于存放 main 函数的参数) 和 hello-x86_64-qemu.o 组成的。用 file 类型可以识别出它:
$ file hello-x86_64-qemu
hello-x86_64-qemu: DOS/MBR boot sector
3.3. 加载
我们在 QEMU 全系统模拟器中运行完整的镜像 hello-x86_64-qemu (包含 hello-x86_64-qemu.o)。如果用一些特别的选项,就能近距离观察模拟器的执行:
$ qemu-system-x86_64 -S -s -serial none -nographic hello-x86_64-qemu
其中:
-S在模拟器初始化完成 (CPU Reset) 后暂停-s启动 gdb 调试服务器,可以使用 gdb 调试模拟器中的程序-serial none忽略串口输入/输出-nographics不启动图形界面
我们可以在终端里启动一个 monitor (Online Judge 就处于这个模式)。在这里,我们就可以像代码课中讲解的那样,直接调试整个 QEMU 虚拟机了!
3.3.1 CPU Reset
就像 NEMU 一样调试虚拟机,我们使用 info registers 查看 CPU Reset 后的寄存器状态。
QEMU 2.11.1 monitor - type 'help' for more information
(qemu) info registers
EAX=00000000 EBX=00000000 ECX=00000000 EDX=00000663
ESI=00000000 EDI=00000000 EBP=00000000 ESP=00000000
EIP=0000fff0 EFL=00000002 [-------] CPL=0 II=0 A20=1 SMM=0 HLT=0
ES =0000 00000000 0000ffff 00009300
CS =f000 ffff0000 0000ffff 00009b00
SS =0000 00000000 0000ffff 00009300
DS =0000 00000000 0000ffff 00009300
FS =0000 00000000 0000ffff 00009300
GS =0000 00000000 0000ffff 00009300
LDT=0000 00000000 0000ffff 00008200
TR =0000 00000000 0000ffff 00008b00
GDT= 00000000 0000ffff
IDT= 00000000 0000ffff
CR0=60000010 CR2=00000000 CR3=00000000 CR4=00000000
DR0=0000000000000000 DR1=0000000000000000 DR2=0000000000000000 DR3=0000000000000000
DR6=00000000ffff0ff0 DR7=0000000000000400
EFER=0000000000000000
FCW=037f FSW=0000 [ST=0] FTW=00 MXCSR=00001f80
FPR0=0000000000000000 0000 FPR1=0000000000000000 0000
FPR2=0000000000000000 0000 FPR3=0000000000000000 0000
FPR4=0000000000000000 0000 FPR5=0000000000000000 0000
FPR6=0000000000000000 0000 FPR7=0000000000000000 0000
XMM00=00000000000000000000000000000000 XMM01=00000000000000000000000000000000
XMM02=00000000000000000000000000000000 XMM03=00000000000000000000000000000000
XMM04=00000000000000000000000000000000 XMM05=00000000000000000000000000000000
XMM06=00000000000000000000000000000000 XMM07=00000000000000000000000000000000
(qemu)
CPU Reset 后的状态涉及很多琐碎的硬件细节,这也是大家感到为 bare-metal 编程很神秘的原因。不过简单来讲,我们关心的状态只有两个:
%cr0 = 0x60000010,最低位PE-bit 为 0,运行在 16-bit 模式 (现在 CPU 的行为就像 8086)%cs = 0xf000,%ip = 0xfff0,相当于 PC 指针位于0xffff0
你甚至可以检查上面打印出的状态和手册的一致性:
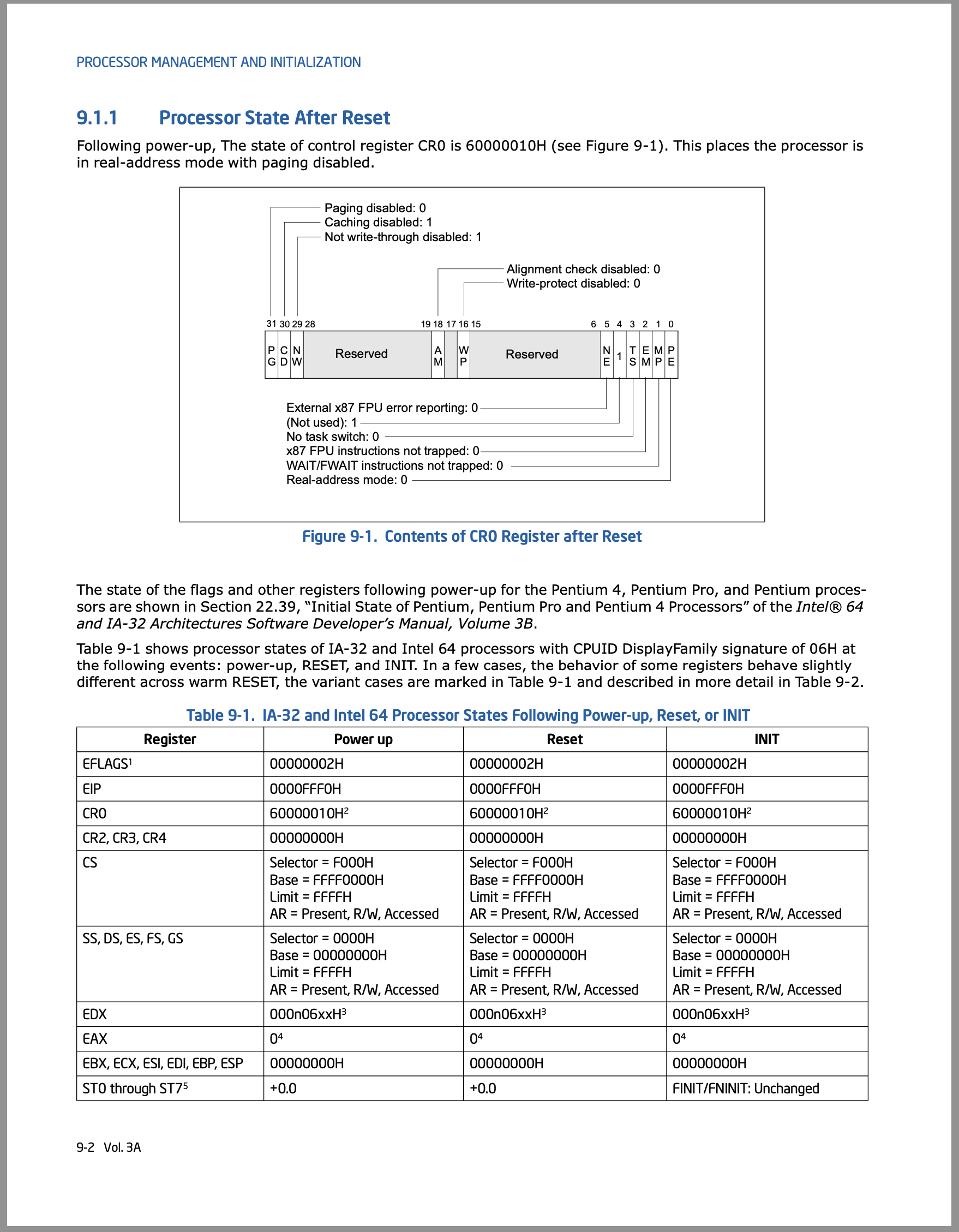
CPU Reset 后,我们的计算机系统就是一个状态机,按照 “每次执行一条指令” 的方式工作。
3.3.2. Firmware: 加载 Master Boot Record
位于 0xffff0 的代码以内存映射的方式映射到只读的存储器 (固件,firmware,也称为 BIOS) 中。固件代码会进行一定的计算机状态检查 (比如著名的 “Keyboard not found, press any key to continue...”)。如果我们在 gdb 中使用 target remote localhost:1234 连接到 qemu (默认端口为 1234),就可以开始单步调试固件代码。
在比较简单的 Legacy BIOS Firmware (Legacy Boot) 模式,固件会依次扫描系统中的存储设备 (磁盘、优盘等,Boot Order 通常可以设置),然后将第一个可启动磁盘的前 512 字节 (主引导扇区, Master Boot Record, MBR) 加载到物理内存的 0x7c00 地址。以下是 AMI 公司在 1990s 的 BIOS Firmware 界面:
今天的 Firmware 有了 UEFI 标准,能更好地提供硬件的抽象、支持固件应用程序——今天的 “BIOS” 甚至有炫酷的图形界面 (不要小看图形界面,能显示图形意味着你得有总线、键盘、鼠标的驱动程序……),固件复杂程度可比小型操作系统;UEFI 加载器也不再仅仅加载是 512 字节的 MBR,而是能加载任意 GPT 分区表上的 FAT 分区中存储的应用。今天的计算机默认都通过 UEFI 引导。
从容易理解的角度,我们编写操作系统时,依然从 Legacy Boot 启动,你只需要知道,在 x86 系统上,AbstractMachine 和 Firmware 的约定是磁盘镜像的前 512 字节将首先会被加载到物理内存中执行。
我们可以通过 gdb 连接到已经启动 (但暂停) 的 qemu 模拟器:
$ gdb
(gdb) target remote localhost:1234
Remote debugging using localhost:1234
0x000000000000fff0 in ?? ()
(gdb) b *0x7c00
Breakpoint 1 at 0x7c00
(gdb) c
Continuing.
Breakpoint 1, 0x0000000000007c00 in ?? ()
(gdb) x/16i $pc
=> 0x7c00: cli
0x7c01: xor %eax,%eax
0x7c03: mov %eax,%ds
0x7c05: mov %eax,%es
0x7c07: mov %eax,%ss
...
使用 layout asm 进行指令级的调试 (调试 16-bit code 时 disassembler 会遇到一些小麻烦,但调试的基本功能是没问题的;借助其他工具如 nasm 可以正确查看代码)。
3.3 Boot Loader: 解析并加载 ELF 文件
在 gdb 中看到的 0x7c00 地址的指令序列是我们的 boot loader 代码,存储在磁盘的前 512 字节。x86-64 的 AbstractMachine 在这 512 字节内完成 ELF 文件的加载。这部分代码位于 am/src/x86/qemu/boot,由一部分 16-bit 汇编 (start.S),主要部分如下:
.code16
.globl _start
_start:
cli
xorw %ax, %ax
movw %ax, %ds
movw %ax, %es
movw %ax, %ss
lgdt gdtdesc
movl %cr0, %eax
orl $CR0_PE, %eax
movl %eax, %cr0
ljmp $GDT_ENTRY(1), $start32
.code32
start32:
movw $GDT_ENTRY(2), %ax
movw %ax, %ds
movw %ax, %es
movw %ax, %ss
movl $0xa000, %esp
call load_kernel
这段代码 (不需要理解) 就是做一些必要的处理器设置,切换到 32-bit 模式,设置初始的栈顶指针 (0xa000),然后跳转到 32-bit C 代码 load_kernel 执行。load_kernel 位于 main.c (有简化):
#include <stdint.h>
#include <elf.h>
#include <x86.h>
// 调用 I/O 指令把磁盘上的数据读到内存指定位置;代码省略
static inline void copy_from_disk(void *buf, int nbytes, int disk_offset);
static void load_program(uint32_t filesz, uint32_t memsz, uint32_t paddr, uint32_t offset) {
copy_from_disk((void *)paddr, filesz, offset);
char *bss = (void *)(paddr + filesz);
for (uint32_t i = filesz; i != memsz; i++) {
*bss++ = 0;
}
}
static void load_elf64(Elf64_Ehdr *elf) {
Elf64_Phdr *ph = (Elf64_Phdr *)((char *)elf + elf->e_phoff);
for (int i = 0; i < elf->e_phnum; i++, ph++) {
load_program(
(uint32_t)ph->p_filesz,
(uint32_t)ph->p_memsz,
(uint32_t)ph->p_paddr,
(uint32_t)ph->p_offset
);
}
}
void load_kernel() {
Elf32_Ehdr *elf32 = (void *)0x8000;
Elf64_Ehdr *elf64 = (void *)0x8000;
int is_ap = boot_record()->is_ap;
// 将 ELF 文件的头部加载到物理地址 0x8000
copy_from_disk(elf32, 4096, 0);
if (elf32->e_machine == EM_X86_64) {
// 加载 ELF 文件
load_elf64(elf64);
// 跳转到 ELF 头指定的入口地址执行
((void(*)())(uint32_t)elf64->e_entry)();
}
}
我们现在只需要知道我们编写的这段代码会被编译链接,然后被放置在磁盘的 MBR,从而被固件自动加载执行。在 load_elf64 中,我们根据 ELF 格式的规定将文件内容载入内存,然后跳转到 ELF 文件的入口,就算完成了 “hello 的加载”。
3.4 _start: 初始化 64-bit Long Mode
此时我们的 hello (以及未来的 “操作系统”) 代码已经开始执行了,不过此时还不能立即执行 main 函数——我们还处于 32-bit 模式。am/src/x86/qemu/start64.S 的代码会完成最后的设置,比较重要的是启动分页 (正确设置四级页表)、切换到 x86-64 Long Mode,然后进入以下 64-bit 代码执行:
.code64
_start64:
movw $0, %ax
movw %ax, %ds
movw %ax, %es
movw %ax, %ss
movw %ax, %fs
movw %ax, %gs
movq $MAINARG_ADDR, %rdi
pushq $0
jmp _start_c
之后,我们就进入了 C 代码的世界;但此时并未完成所有的初始化,在 trm.c 中的代码还要完成一系列硬件/运行环境的初始化:
void _start_c(char *args) {
if (!boot_record()->is_ap) {
// 第一个处理器
__am_bootcpu_init();
stack_switch_call(
stack_top(&CPU->stack), // 切换到 percpu 的栈;思考题:为什么??
call_main, // 执行 call_main(args)
(uintptr_t)args
);
} else {
// 其他处理器
__am_othercpu_entry();
}
}
void __am_bootcpu_init() {
heap = __am_heap_init(); // 获得物理内存大小
__am_lapic_init(); // 初始化中断控制器
__am_ioapic_init();
__am_percpu_init(); // 其他处理器相关的初始化
}
最后,完成堆栈切换,然后调用 call_main 函数:
static void call_main(const char *args) {
halt(main(args));
}
Say hello 的 main 此时才正式开始执行,真是一段漫长的旅途!
把它们都忘了吧!
作为对你读到这里耐心的嘉奖,允许你把之前发生的事情都忘记。你只需要知道在
main函数运行的时候,C 语言的运行时环境已经完全初始化好 (代码、数据、堆区、栈区),并且 C 代码可以调用一些库函数。
3.3.4. Bare-Metal 上的程序
C 程序编译后得到的指令序列终于在 bare-metal 上开始运行。
和操作系统上的 C 程序不同,AbstractMachine 上的程序对计算机硬件系统有完整的控制,甚至可以链接汇编代码或使用内联汇编 (inline assembly) 访问系统指令。我们可以在 bare-metal 上编写各种 non-trival 的程序,例如任何小游戏 (参考 OS Lab 0),其中使用 I/O 指令和 memory-mapped I/O 直接和物理设备交互,读取系统时间和按键、更新屏幕。
最后,操作系统
在《操作系统》课程实验中,操作系统也是 AbstractMachine 上的一个程序。在我们终于可以抛出这个十分经典的说法:“操作系统就是一个 C 程序”。操作系统内核的源代码 (若干
.c文件和 AbstractMachien API 库) 经过 (刚才描述的、漫长的) 编译和链接生成二进制文件,然后被保存到存储设备中,由加载器加载运行。从原理上说,操作系统不过如此。
