机器学习:既计算密集,又数据密集
![]()
GPT-3: Language models are few-shot learners
- Transformer 架构
- 175B 参数 (~300GB VRAM, FP-16)
- GPT-3 single training run cost: ~$5,000,000
- 美国人断供芯片 = 三体人行为
- 320TB 语料
- 相比图片和视频,还是小弟弟
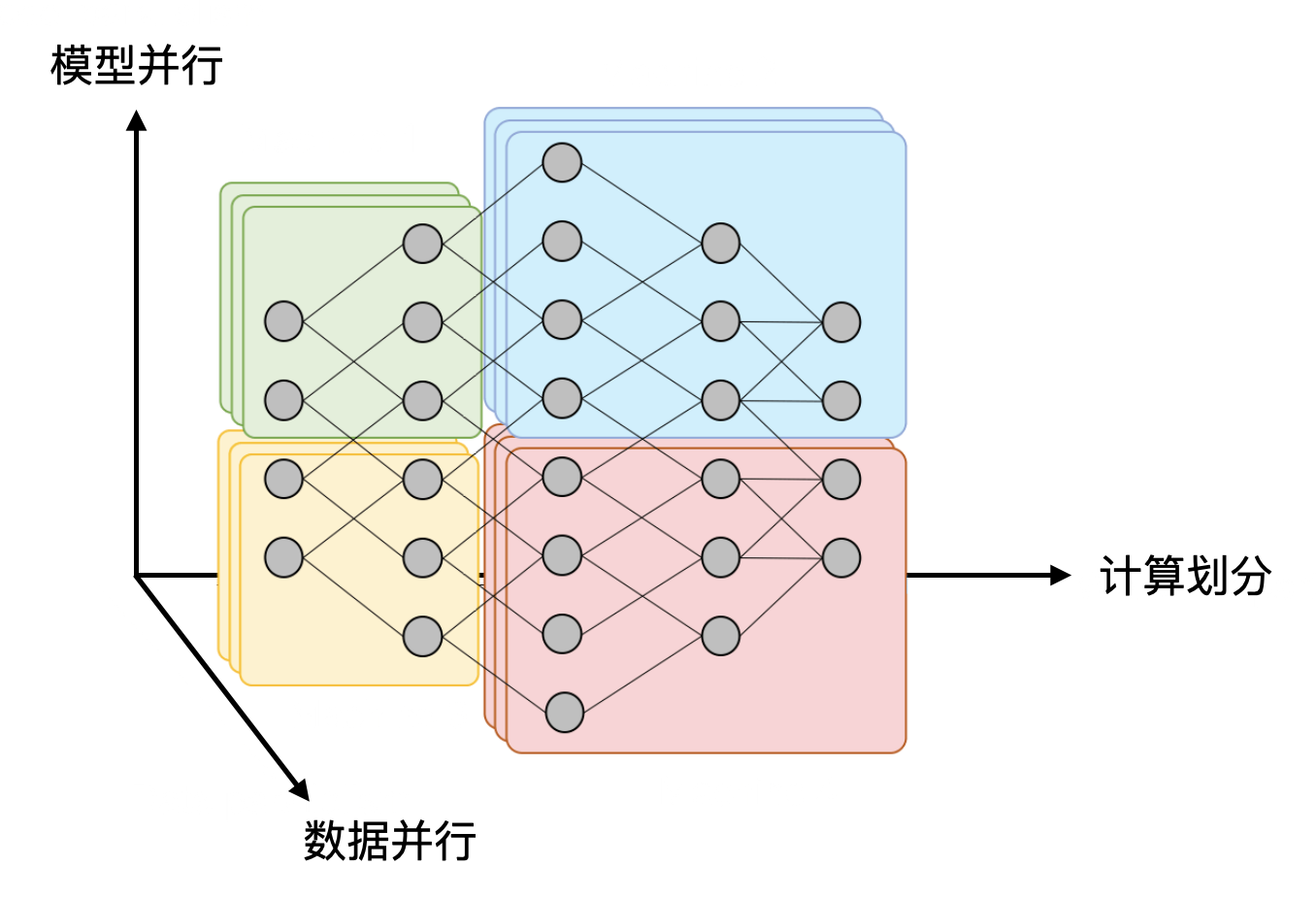
并行化:Dependency Graph is All You Need
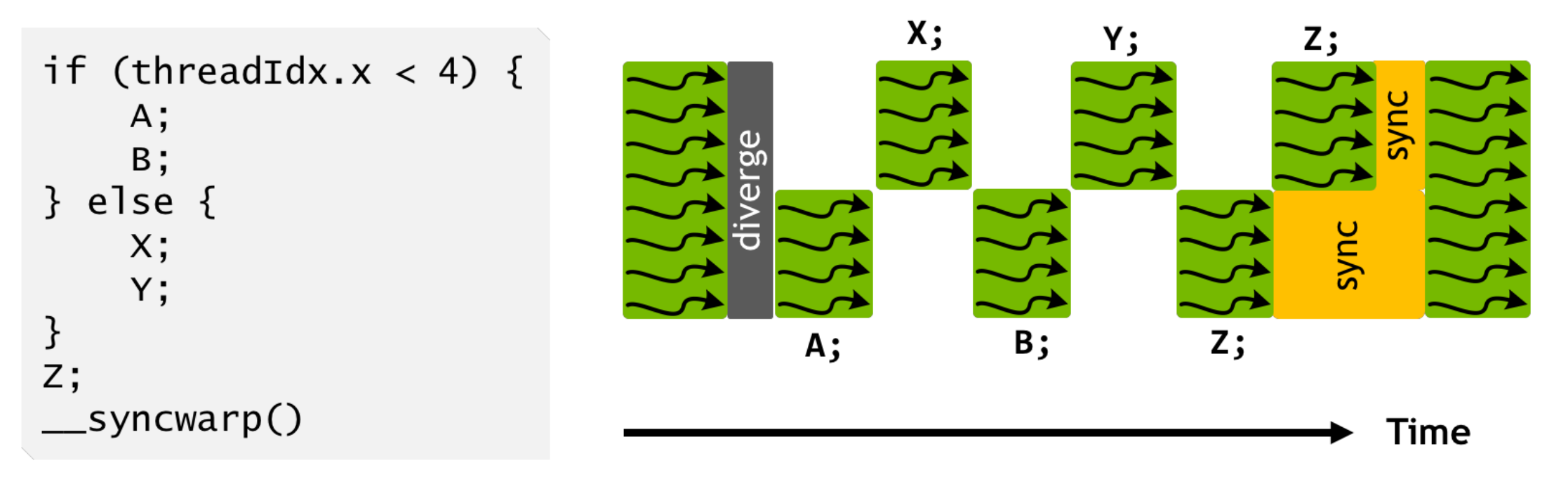
计算密集部分 (1):SIMT
Single Instruction, Multiple Threads
- 一个 PC,控制 32 个执行流同时执行
- 逻辑线程可以更多
- 执行流有独立的寄存器
- $x, y, z$ 三个寄存器用于标记 “线程号”,决定线程执行的动作
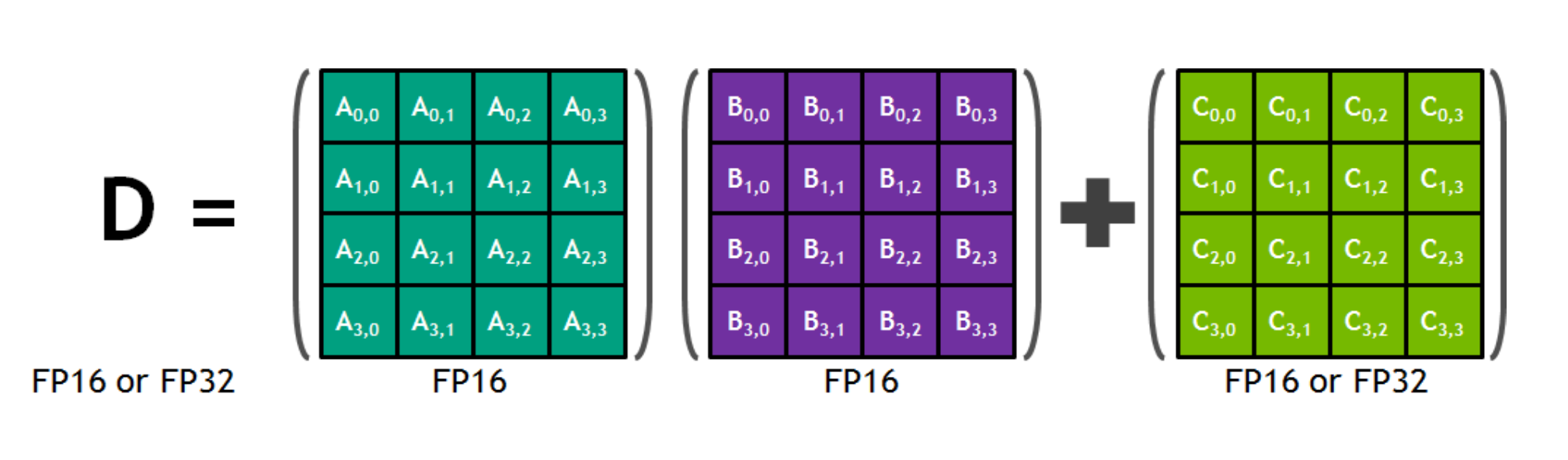
计算密集部分 (2):SIMD
Single Instruction, Multiple Data
- Tensor 指令 (Tensor Core):混合精度 $A \times B + C$
- 单条指令完成 $4\times4\times4$ 个乘法运算
计算密集部分 (3):堆更多的处理单元!
GH100 Spec
- 144 SMs
- 18432 CUDA Cores (并行的 Threads)
- AVX512: 512bits = 16 x Float32
- 576 Tensor Cores (4 per SM)
- 6 HBM3 or HBM2e stacks
- 12 512-bit memory controllers
- 60 MB L2 cache
这只是一个 GPU
- 显存/缓存决定了 GPU 内堆处理器的上限
- 但我们可以有多台机器、每个机器有多台 GPU!
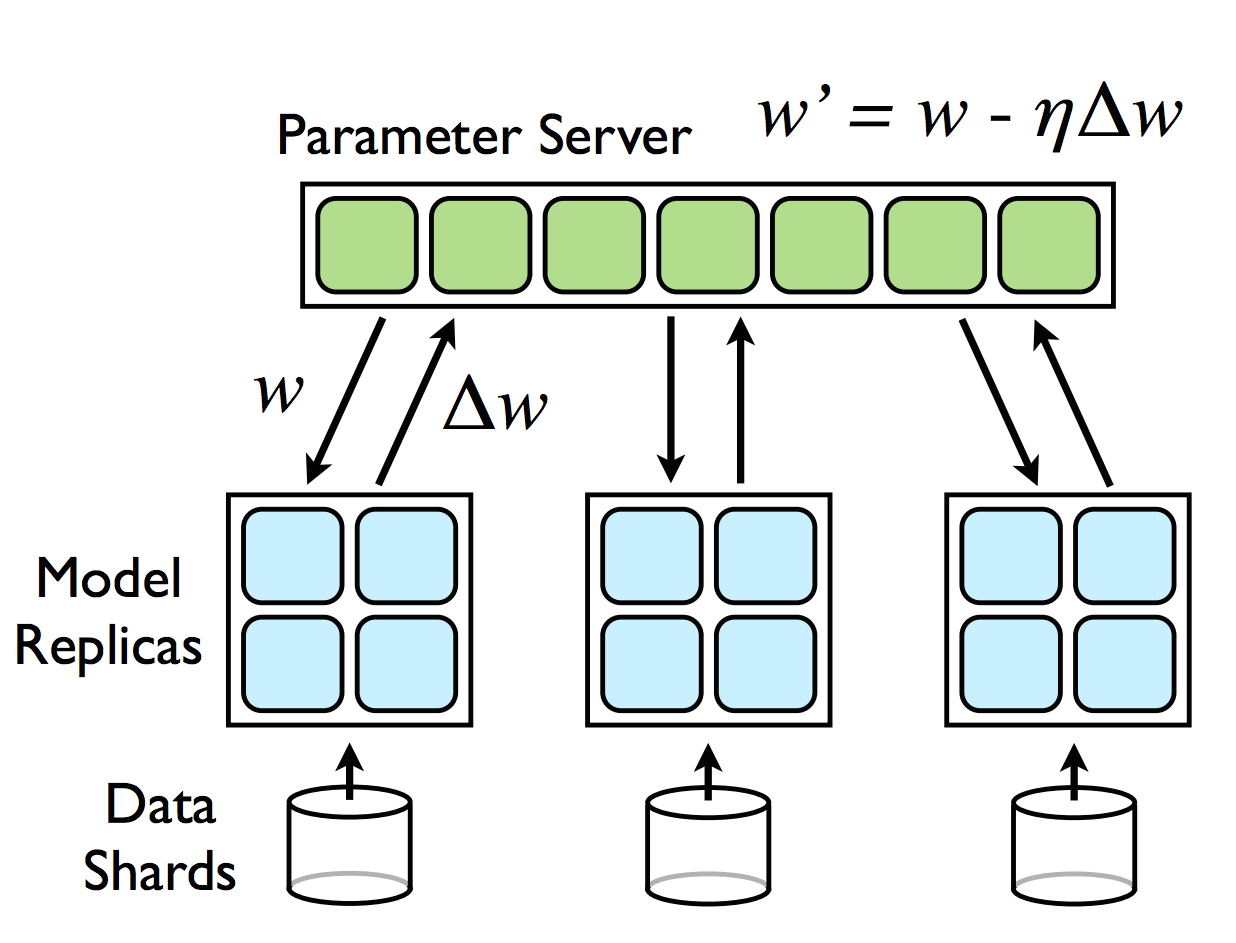
分布式机器学习
高性能计算 (GPU) + 数据中心计算