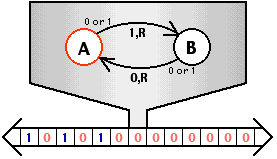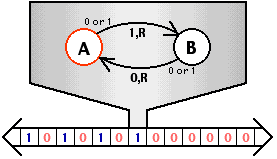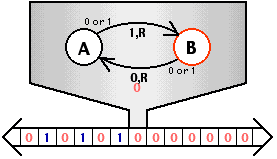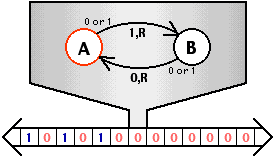
AbstractMachine: TRM
Turing Machine: 一个处理器,一个地址空间
- “无情的执行指令的机器” (rvemu) 的抽象
- 可用的内存是静态变量和
heap - 只能执行计算指令和 putch, halt
AbstractMachine: MPE
Multiprocessing Extension: 多个处理器,一个地址空间
- 可用的地址空间依然是静态变量和
heap(处理器间共享) - “多个 Turing Machine,共享一个纸带”
状态机模型发生了改变
- 状态:共享内存和每个处理器的内部状态 $$(M, R_1, R_2, \ldots, R_n)$$
- 状态迁移:处理器 $t$ 分隔出一个 “单处理器计算机”
- 执行 $(M, R_t) \to (M', R_t')$ $$(M, R_1, R_2, \ldots, R_n) \to (M', R_1, R_2, \ldots, R_t', \ldots, R_n)$$
简易多处理器内核 (L1 的模型)
与多线程程序完全一致
- 同步仅能通过原子指令如
xchg实现
uint8_t shm[MEM_SIZE]; // Shared memory
void Tprocessor() {
struct cpu_state s;
while (1) {
fetch_decode_exec(&s, shm);
}
}
int main() {
for (int i = 0; i < NPROC; i++) {
create(Tprocessor);
}
}