崩溃一致性 (Crash Consistency)
Crash Consistency: Move the file system from one consistent state (e.g., before the file got appended to) to another atomically (e.g., after the inode, bitmap, and new data block have been written to disk).
磁盘不提供多块读写 “all or nothing” 的支持
- 甚至为了性能,没有顺序保证
- bwrite 可能被乱序
- 所以磁盘还提供了 bflush 等待已写入的数据落盘
File System Checking (FSCK)
根据磁盘上已有的信息,恢复出 “最可能” 的数据结构
- SQCK: A declarative file system checker (OSDI'08)
- Towards robust file system checkers (FAST'18)
- “widely used file systems (EXT4, XFS, BtrFS, and F2FS) may leave the file system in an uncorrectable state if the repair procedure is interrupted unexpectedly” 😂
针对 crash,我们需要更可靠的方法我们需要一个更可靠的方法
- 文件系统不一致的根本原因是
存储设备无法提供多次写入的原子性
重新思考数据结构的存储
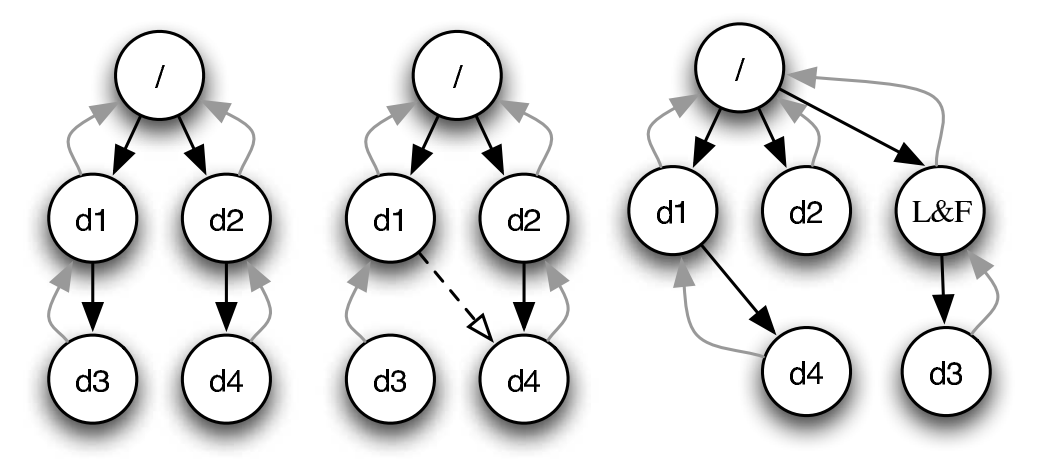
两个 “视角”
- 存储实际
数据结构 - 文件系统的 “直观” 表示
- crash unsafe
- Append-only 记录所有
历史操作 - “重做” 所有操作得到数据结构的当前状态
- 容易实现崩溃一致性
二者的融合
- 数据结构操作发生时,用 (2) append-only 记录日志
- 日志落盘后,用 (1) 更新数据结构
- 崩溃后,重放日志并清除 (称为 redo log;相应也可以 undo log)
实现 Atomic Append
用 bread, bwrite 和 bflush 实现 append()
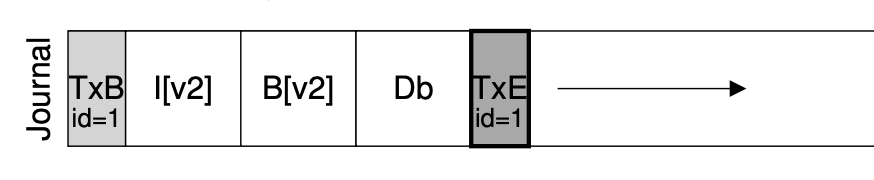
- 定位到 journal 的末尾 (bread)
- bwrite TXBegin 和所有数据结构操作
- bflush 等待数据落盘
- bwrite TXEnd
- bflush 等待数据落盘
- 将数据结构操作写入实际数据结构区域
- 等待数据落盘后,删除 (标记) 日志
Journaling: 优化
现在磁盘需要写入双份的数据
- 批处理 (xv6; jbd)
- 多次系统调用的 Tx 合并成一个,减少 log 的大小
- jbd: 定期 write back
- Checksum (ext4)
- 不再标记 TxBegin/TxEnd
- 直接标记 Tx 的长度和 checksum
- Metadata journaling (ext4 default)
- 数据占磁盘写入的绝大部分
- 只对 inode 和 bitmap 做 journaling 可以提高性能
- 保证文件系统的目录结构是一致的;但数据可能丢失
- 数据占磁盘写入的绝大部分
Metadata Journaling
从应用视角来看,文件系统的行为可能很怪异
- 各类系统软件 (git, sqlite, gdbm, ...) 不幸中招
- All file systems are not created equal: On the complexity of crafting crash-consistent applications (OSDI'14)
- (os-workbench 里的小秘密)
- 更多的应用程序可能发生 data loss
- 我们的工作: GNU coreutils, gmake, gzip, ... 也有问题
- Crash consistency validation made easy (FSE'16)
更为一劳永逸的方案:TxOS
- xbegin/xend/xabort 系统调用实现跨 syscall 的 “all-or-nothing”
- 应用场景:数据更新、软件更新、check-use……
- Operating systems transactions (SOSP'09)